Development
- Feb 15 2013 - I am a technology tourist (or first impressions of Dart) ... So this week I met with someone who was very excited about working with Google Dart, a web programming language aimed at being a better JavaScript running both on the server and ultimately the client where the VM could run in browsers (only chromium for now). When Google first announced Dart in September '11 I thought "cool, too bad it will never work" and basically dismissed the project as doomed since it would presumably face too much pressure from competitors and open standards. After the failures of Flash, Java (applets) and most recently Silverlight it's hard to imagine Google having an ability to convince the world to abandon JavaScript in favor of Dart. Even GWT seems to be losing Google's attention somewhat. Having just been burned my MSFT on Silverlight I am overly wary of any proprietary tech these days.
But what I overlooked when I initially dismissed dart was the dart2js compiler and the fact that Dart doesn't really need the Dart VM to succeed for the language to get some traction. So skepticism temporarily put on hold I decided to port a small existing project from jQuery to Dart. The project was pretty simplistic, about 175 lines of Javascript served up statically and allowing users to navigate a full page grid with vim-like keybindings, entering free flowing text in "contenteditable" divs within the grid.
Some thoughts on the experience:- Dart editor based on eclipse is handy and the integration with chromium made the whole experience of getting up and running with the SDK really easy
- Classes! Optional Types! (or ?) Libraries! Isolates! Lexical Scoping! All very nice and immediately familiar in the resulting code.. although I did find myself momentarily confused by:
- lack of object notation (use Maps instead)
- lack of dot access to those map properties
- lack of explicit private keyword (use _prefix to indicate private)
- lack of string concatenation (use string interpolation, which I actually really like)
- handling of concurrency is really interesting not just in the Isolates but also in the "Future" type which makes for some really clean chaining of asynchronous calls such that you are not nesting N levels of callback functions. Didn't use them but they looked cool.
- There are equivalents in the "dart:html" library for a lot of what you'd commonly reach for in jQuery, but in general I found myself writing more verbose code than what I was doing equivalently in jQuery. That said...
- I had WAY fewer error cycles in Dart, and the semi-static typing made the whole conversion process take only a couple hours including all the time spent looking things up..
- ... and looking things up was pretty easy, you can tell it's largely from Google but they are investing enough in their docs that it was always pretty easy to get what I needed
- A nagging feeling... While dom manipulation was straight forward I found myself cut off from Javascript. It looks as though calling between them is totally doable but feels hacky as soon as you go down that path. Dart itself assumes just enough responsibility that leaving the core libraries feels like foreign territory effectively isolating you off from all of the innovation happening out there in Javascript land. I may be making a mountain out of a molehill here but having to choose between Dart native libraries and Javascript community for common tasks is not pleasant.
So all in all it was a really positive experience, the tooling is solid, the language itself is very comfortable for someone with my background and I can see clear advantages especially on a larger project. But I'm now at crossroads on this little project, do I go with the comfortable tools and language with questions around the long term viability and community support for the proprietary Dart (to be fair it's open source, but open source doesn't remove the fact that this is very much a Google initiative) or do I stick with the "open web" and just deal with all the pains?..... After a couple days and writing this out I decided I just can't commit to Dart yet. There's too many exciting developments happening in the open web and Dart feels too much like unnecessary fragmentation of the collective efforts to improve things. Will be keeping an eye on this though, just because it's cool. The project's ambition is admirable and it feels like they are just getting started.
After a couple days and writing this out I decided I just can't commit to Dart yet. There's too many exciting developments happening in the open web and Dart feels too much like unnecessary fragmentation of the collective efforts to improve things. Will be keeping an eye on this though, just because it's cool. The project's ambition is admirable and it feels like they are just getting started. - Feb 14 2013 - How does vim keep sucking me in? ... I "grew up" on vim, which is to say my second professional programming job 15 years ago required me to spend vast quantities of time in a terminal to a Solaris machine on which I used vi exclusively to get work done. In those two years I got relatively proficient at navigation, search and replacing, using registers, and tweaking .vimrc with custom settings and macros. I did NOT get into folding, window management, syntax highlighting, or plugins. Things have changed a lot in vim-land.
 Watching a friend operate vim last week triggered weirdly intense pangs of jealousy and masochistic visions of how I too could suffer through horrible learning curves and bouts of frustration in order to eke out those extra few moments of productivity per day. How I too could spend hours meddling with plugins and hacks, custom scripts and a terminal to get features which every modern IDE user now takes for granted. I romantically pictured my hands rooted on the homekeys, flying through mountains of text like a boss, and the legions of adoring co-workers who would wonder at my elite skills. Totally will happen.
Watching a friend operate vim last week triggered weirdly intense pangs of jealousy and masochistic visions of how I too could suffer through horrible learning curves and bouts of frustration in order to eke out those extra few moments of productivity per day. How I too could spend hours meddling with plugins and hacks, custom scripts and a terminal to get features which every modern IDE user now takes for granted. I romantically pictured my hands rooted on the homekeys, flying through mountains of text like a boss, and the legions of adoring co-workers who would wonder at my elite skills. Totally will happen.
So for what feels like the Nth time, I re-approached my old friend vim. It was shocking how much of my muscle memory had been retained, but it was also shocking how much I miss features like "find usages", "refactor...[anything]" and quick project based shortcuts for getting around files. One of the plugins my friend was using was NERDTree, which provides a pretty nifty tree project/folder navigator as a window in vim. Almost but not quite a project view.
And when it comes to plugins, all the cool kids these days are using the social git-goodness of github combined with a neat plugin called Pathogen to create "dotVim" repositories which make the whole process of managing, sharing, and installing your perfect vim environment far far simpler. Branch a dotVim repo, symlink it into your user folder and you're off. You'll find a ton of documentation out there on how to make it work so I won't repeat it here. I based my latest attempt at vim heaven on Kody Krieger's dotVim, which is a slimmed down version of Janus which uses Pathogen. I particularly liked that installation of this is bootstrapped so you can run a single command in the console to get started: (which of course I had to inspect before running because I'm paranoid like that)
curl https://raw.github.com/codykrieger/dotvim/master/bootstrap.sh -o - | sh
Anyway, after dealing with some issues as a result of missing plugins (slim, which looks to be fixed since I installed) I was off and running. I ended up deleting the ruby specific plugins and adding a few color schemes but have otherwise only changed the .vimrc (macros, and tabs not spaces damnit! unless it's python, then spaces are ok)
NERDTree is great, but I find myself still relying on good ole :e for most things
Ctrl-P is fantastic but I find it doesn't always work, I'm guessing I need to feed more information about my context to it so that it searches the right paths. When it does work though it's basically :e on steroids.
Fugitive is amazing, and the ability to quickly pull up a diff on what you're working on is lovely. I still hit the command line more often than I probably need to.
There are a bunch of others in here that are probably making life nicer without me even knowing...still much to learn.
I quite like the git repo approach and the fact that I was able to tweak everything on my laptop and then just clone to my desktop at home was pretty fantastic. I will say though that I find the sub-modules a bit of a nuisance. I don't really need to be on the bleeding edge of vim plugins and I'd rather have full control so I removed all of the submodule aspects to the above dotVim and will just pull updates when I hit bugs or need new features. The end result of my efforts are on bitbucket.
To commit myself more to learning the editor I've also started using it for writing simple text documents as well like the government forms I'm in the process of filling out. It's fun to make a terrible job an opportunity to refine your tool skills. Vim out of the box is not great at handling paragraphs of text however and so a few tweaks are required. I have the following in my .vimrc which allows me to quickly enter "prose" mode (fixing line up line down in wrap mode being the biggest element for me)
" setup the current vim instance for writing prose style
command! Prose call SetupForProse()
function SetupForProse()
"break lines visually, and don't group hardbreaks on previous word
set formatoptions=1
set linebreak
set wrap
set nolist
"set breakat=\ |@-+;:,./?^|
"change default cursor keys to work on visual not actual lines
nnoremap j gj
nnoremap k gk
vnoremap j gj
vnoremap k gk
"border on the left hand side
set foldcolumn=7
endfunction
On with the self torture! - Oct 7 2010 - lowering impedance of TDD with python mock ...
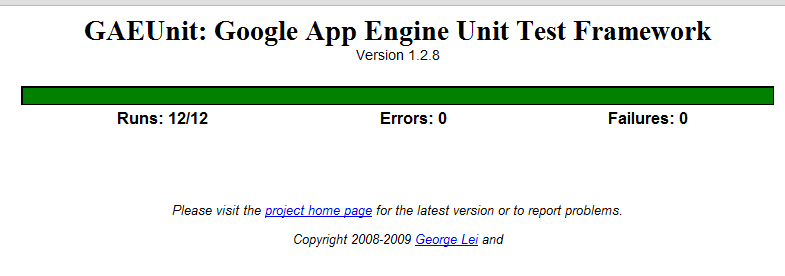
So after my post about gaeunit a few weeks ago I’ve since completely thrown out what I was doing there and moved to vanilla python unit tests. I ended up making this move for a few reasons.
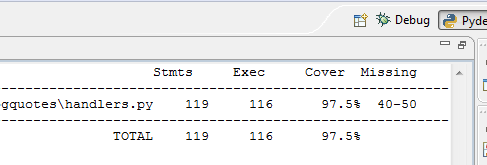
1. I was never running my tests.- GAEUnit was nice, but slow. Even when running tests in parallel I still had to go through the process of opening the browser, navigating to the right place and letting the tests run. Compare this to ctrl-f9 and seeing the following:
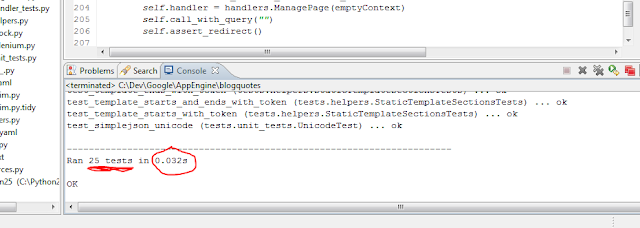 2. AND I love seeing code coverage numbers and while it might actually be possible with GAEUnit, it wasn’t this easy…
2. AND I love seeing code coverage numbers and while it might actually be possible with GAEUnit, it wasn’t this easy…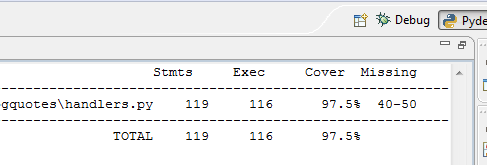 In the end it was relatively simple once I started employing mocking to deal with sessions and realized that I could actually issue real request objects to my handlers with relative ease…webObReq = Request.blank(url)webApReq = webapp.Request(webObReq.environ)handler.initialize(webApReq, webapp.Response())For the mocking I eventually decided to go with this framework:It has so far been fine for my needs and at least my handlers have almost achieved 100% coverage. The syntax is a little foreign compared to Moq, but hasn’t been a blocker to me actually getting work done so I’d recommend it.
In the end it was relatively simple once I started employing mocking to deal with sessions and realized that I could actually issue real request objects to my handlers with relative ease…webObReq = Request.blank(url)webApReq = webapp.Request(webObReq.environ)handler.initialize(webApReq, webapp.Response())For the mocking I eventually decided to go with this framework:It has so far been fine for my needs and at least my handlers have almost achieved 100% coverage. The syntax is a little foreign compared to Moq, but hasn’t been a blocker to me actually getting work done so I’d recommend it. - Sep 21 2010 - Engineering Management (link) ...
Great article(s) on some of the management principles in the engineering group at Facebook from Yishan Wong who was at Facebook through some very interesting growth times. I found reading this to be inspirational so posting for posterity…
http://algeri-wong.com/yishan/engineering-management.html - Sep 15 2010 - I just quit my job.... ...
Ha! No I didn’t. But starting on the premise that I had and I had already saved a bunch of cash and decided to finally become my own boss, what would I do first?
For me this is hypothetical, but for my good friend who’s about to make the leap out of full time employment to self employment it is very very real. And so I will live vicariously and imagine what I’d do.
The Goal:- build a business that can at a minimum support me before my year of savings has run out so that I can continue to build said business long enough affect real change and or make loads of cash
My Challenges:- I have enough money to sustain myself for the year, or to invest and sustain myself for less
- I love to program. I love to program, and specifically solve technical problems, so much that I focus on it to the detriment of other tasks. (like writing business plans, talking to users or bathing)
- I have a set of real technical hurdles to clear in order to have anything of value
My Assets:- A good idea
- Mad programming skills
- Friends in medium places
 (caveat that this is an hour’s worth of dumping thoughts based on a few conversations and some latent thought) ;-)My first steps:
(caveat that this is an hour’s worth of dumping thoughts based on a few conversations and some latent thought) ;-)My first steps:- Set some very high level goals (these can change)
- Month 1 initial Product Plan is ready (see below)
- Month 1 website is up, domain is secured (even if a teaser)
- Month 2 delivering live usable software with weekly updates for the remainder of the year
- Month 3 gut check milestone - pull the plug or keep going?
- Month 4 gut check milestone - go alone or go big? do I need more money?
- Month 5 gut check milestone - pull the plug or keep going?
- Month 6 target - engaged user community is built and driving the backlog (uservoice)
- Month 6 target - marketing (adsense? viral? user communities?)
- Month 8 target - earn my first dollar
- Months 9 gut check - is this a venture someone would buy? should I start talking to those people?
- months 10-11 - rinse and repeat, drive drive drive
- Month 12 - profit!
- Make a workspace
- Seclusion, powerful machine, dual monitors, natural lighting, huge whiteboard, music and snacks
- block reddit.com from this network
- have a laptop available for games, surfing etc - try however possible to keep these separate
- Make a development environment
- IDE, tools, etc
- source control
- continuous integration with all the trimmings
- Start building!
- For at least two days a week early on, or maybe a couple hours a day in the beginning besides building I would ALSO do the following…. (Product Plan)
- Write myself a short Vision and Scope document which would include:
- The elevator pitch, preferably in a single sentence which I would then post on a wall in my workspace
- The high level guiding principles for the need I’m trying to solve, how I’ll translate that into some revenue (not overly specific), who I’m targeting, who my competitors may be and what the biggest risks are.
- I would do this loosely, but I would do it. Just the act of looking and solidifying my direction would be motivating.
- Build a backlog of features, ideally written in the style of “As a <<user>> I want <<to do something>> so that <<some value>>"
- Make a persona or two or three based on the largest value user segments
- Pick one persona who I can deliver something of value to
- Prioritize my backlog with this user type in mind, and work backwards to find the minimum viable product that could actually be used by a user. This is my first milestone.
- Look for ways to accelerate getting to revenue sooner.
- Look around for ways to extend the 12 months without too much distraction (grants etc)
- Network network network. A lot of my milestones might be easier with help. Socialize that I’m up to something even if I’m not giving away the secret sauce.
- Force myself to join some local developer user groups that align to my technology choices
- force myself to attend some tech talks and socialize with other technologists
- guarantee that at least some evenings are spent away from my work
- Refer to my 12 month road-map on a weekly basis. (Monday morning when I’m slow)
- Change it whenever
- Where will I deploy? How will I deploy? I only have two months before it needs to be live in some form so figure that out.
- Will finding my initial target user be difficult? Start hunting early
- What questions will I need to ask in order to answer my gut check milestones? Ask those early.
- Are there components I should look to buy or rent rather than build? How do those align to my backlog?
- How could I accelerate delivery of features? Can some things be outsourced? Should my backlog be altered to allow my investment decision in month four?
- What else might I need to make a go big decision in month four? Do I need a more formal business plan? Do I need to incorporate?
- Continue to build like mad!!
- Profit!!
- Aug 20 2010 - Unicode woes and Python unit testing in GAE ...
One of the really cool aspects of deploying to Google’s cloud offering (GAE) versus the more machine oriented Microsoft Azure and Amazon EC2 approaches are that you really are only dealing with computing resources. You deploy your app not to any particular server, but to the cloud itself. Despite the very real challenges in distributing work across data centers I am still filled with visions of automagical propagation and distribution and unlimited elastic computing. Beautiful. Anyway I was inspecting the logs and was SHOCKED to discover that there have been close to a thousand quotes added to system by 37 users. THIRTY SEVEN USERS!! Now, these are small numbers I know, but given the only publicity I’ve ever given this has been the two posts on this blog I was absolutely amazed to find that people had not only managed to find the app but were able to use it! (It’s quite ugly)
There is nothing quite as motivating as having users.
So I started looking at log files and discovered that I am actually throwing errors for at least some of those users who are not English speaking and are using Unicode characters. Oops. You’d think I’d know better by now. See : The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
In most cases for these bugs it just meant calls to unicode(var) rather than str(var) . So for example when parsing url variables starting with the example provided here by Google and adding my own processing of an array of arguments to a method like so…
def update_field(self, fieldName, *args):
strings = [str(arg) for arg in args]
….
return
and then calling that code with a unicode character such as ‘’–" would produce an error that looked like this…UnicodeEncodeError: ‘ascii’ codec can’t encode character u’\u2013’ in position 0: ordinal not in range(128)
the same code as above corrected is below. There were a few variants on this but this is a good example of a function where user defined input dictated a change to accommodate.def update_field(self, fieldName, *args):strings = [unicode(arg) for arg in args]….return
So in the course of digging in and finding/fixing these bugs I also recognized I was far overdue for some unit testing. So starting with the premise that I needed a way to reproduce the issue in the lab and write a failing test for this bug I went in search of the best method to do so. Python actually has [pretty good unit test support] built-in but I was also looking for something that would work in the context of GAE. It doesn’t take much looking before stumbling on GAEUnit, which is a useful extension that provides some scaffolding for tests that will run within GAE. The major negative to this is that your tests are part of your application, but I don’t have a problem with that as it’s easy to secure them to administrator access only but for some people it’s a block.
The next issue I ran into with this was the fact that the python SDK for GAE doesn’t include a method for testing content behind authentication. So whereas in Java you can say this :private final LocalServiceTestHelper helper =
new LocalServiceTestHelper(new LocalUserServiceTestConfig())
.setEnvIsAdmin(true).setEnvIsLoggedIn(true);public void testIsAdmin() {
UserService userService = UserServiceFactory.getUserService();
assertTrue(userService.isUserAdmin());
}
But today there is no equivalent for that in python. I wasted a few hours trying to work around this issue before deciding to just login before I run tests. My login lasts for hours so this isn’t much of a constraint. In the long run I plan to drop Google’s authentication any and move to janrain/rpx to allow users to login using whatever they like. That will mean abandoning or at least shimming the infrastructure provided by GAE, but has the additional benefit of reducing my applications direct dependency on Google. Once I have my own definition of Session and session provider I can of course mock it out and control it a lot easier.
Here’s the test, no asserts but if there is a problem we’ll see an exception
def test_unicode_to_json_error(self):
badQuote = q.Quote(quote=‘hi there ’ + u"\u2013")
result = badQuote.jsonSafe()
simplejson.dumps(result)
So one error-type in the log file later I’ve spent a couple days, done a bunch of refactoring and have produced no new functionality… but I do have this!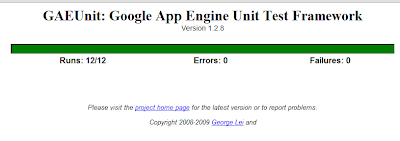
Of course then, after all that I STILL ran into an error with the JavaScript, for which I have yet to add unit testing for. Sigh. I’ll have to choose between qUnit which I’ve used before and YUI-test which is probably better aligned to the rest of my application.
The JavaScript portion of this bug was basically because I was calling unescape() on a url-encoded variable. URL encoding though only supports 8-bit characters and doesn’t truly allow unicode, so my unicode characters became three ascii characters which could include control characters or other undesired results. There seems to be a lot of people standardizing on UTF-8 within url-encoded variables but it’s purely a convention at this point. Thankfully I found this pre-written code on webtoolkit.info that knows how to do the look ahead at the next three characters in order to handle UTF-8 input properly.
Now I hope it’s safe to say that blogquotes can handle unicode! (and has some unit tests to boot!) - May 30 2010 - Flying at the right altitude - advice to a slightly younger me ...
No posts in five months! Almost exactly the same time I’ve been in a new position at work.
Disturbing trends, this completely predates just the last six months…. I’ve moved from being a team lead to being the head of our R&D group. I now have as many teams (7) as I did people to think about, and a whole new world of politics, strategy and planning. With a group of this size HR issues seem to be at least a weekly occurrence and I am now fully and completely on the manager’s schedule.However now that I’ve somewhat got my sea legs in this position I am increasingly allowing myself to get back into technical issues where I think I can add value. “Where I think I can add value” is the whole challenge here though. I have literally not opened visual studio in five months of running around like a chicken with my head cut off. How often does having the boss swoop in and give their less informed perspective do more harm than good? Impossible to answer without knowing the boss in question of course, but surely there are ground rules some sage masters can teach me.I have to say I really enjoy looking at things from this altitude, in that you really can see patterns in development across teams, opportunities for reuse or better design across teams, efficiencies to be gained etc. It all can be very fun, but at the same time I worry about losing relevance, and I worry about sidetracking teams. Even worse is the feeling that by interfering I actually hurt the autonomy and self-sufficiency of these teams by interfering (which almost outweighs the fear of divergent or teams).Here are some things I think I would tell the me of six months ago: (advice to a new executive)- Don’t stop the old routine completely. I actually think a lot of my comfort these days is precisely because I’m getting back to things like my reader and blogger. Just imagine how nice it would be if I could do the occasional code review or bug fix! (unlikely) My life has gotten decidedly more stressful (father died, promotion, second child all within the last six months) and my routine has out of nowhere incorporated quite a bit of gaming all of sudden. (COD2 MW, WoW) Good stress releases but I need to get myself back into creating rather than just consuming things.
- Embrace the manager’s schedule, but respect the maker’s schedule. It’s a very tricky thing not to let your new found schedule dictate awkward length and times for meetings with the people who are there to actually do the development. Resist the urge and find ways to be more effective with meetings. It is SO easy to forget the real costs around this.
- Don’t seek consensus on every decision. It can work on a team of seven or eight to drive for consensus and try to win minds but on much larger teams you’re going to have to get used to making some calls without the comfort of knowing you have everyone on board. Of course reasonable efforts still need to be made but it becomes about key people and finding the influence in the group.
- Be open and give status frequently. Still one I struggle to do properly but it really is key. I am trying right now to really focus on problems at the request of my boss, but don’t forget to acknowledge the wins as well. The more open you are about the warts the easier it is to excise them. In my opinion, maybe counter intuitively, more shit should flow up and more sunshine down. (though that’s an easy one to over generalize)
- Trust and trusting your gut. Not really anything new to the position, but the frequency with which I’ve run into this has gone through the roof. You often just know the right course of action. Waiting to find out the hard way (or expensive way) that you were right can be painful. Trusting yourself is only second to trusting your people. Trust your gut on your people, make sure you have the right people and put that trust in them.
- There will be a lot of water sprayed at your back, be the duck. Or, in other words, find a way to regain your slack.

- Dec 5 2009 - build it (so it's easy) and they will come (make the right decision) ...
One of the biggest lessons I think I’ve learned over the past few years is that you have to be very careful with what you make easy to do in a software system.

When you are working within a preexisting system, it is very hard to work effectively outside the bounds of that system. Whether you are limited by time constraints, peer pressure, political decisions or just pure technical inertia, those early/legacy decisions in a system will have long reaching impacts on the decisions of those who follow.
I’ll give you an example. On a product I worked on for years, the decision to use an object relational mapper (ORM) in early stages was based on a desire to eliminate boilerplate code, reduce the learning curve for new developers and generally push the development of new entities down to the entire team rather than specializing this role in one person. All in all the reasoning was sound, but the inability to see some of the psychological aspects that would impact the future had some serious impact on the future of the system.- Developers stop thinking about database impacts because they never really SEE the database
- The object model and the schema become inexorably tied
- Accessibility to the DAL ends up being given to junior developers who may not have otherwise dealt with it yet.**
- Things that could reasonably be built OUTSIDE the ORM end up dropped in without consideration because developers are following the template.
This can be avoided by having data contracts that are specific to the DAL
** There is nothing inherently wrong with ORM, and if your DAL is properly abstracted so that the ORM isn’t propagated throughout the stack then this too isn’t necessarily a problem.
I add those two caveats because I really don’t have an issue with ORM, in fact I think used properly it makes way more sense then to waste days of development doing repetitive and simple CRUD work.
However the deeper issues that arose for us still focused on convenience. It was convenient to expose the friendly querying methods of the domain objects that mapped to our tables directly to the business logic assemblies. It was convenient to let junior developers write code that accessed those objects as if retrieval and persistence were magically O(1) operations. Of course in reality we discovered embarrassingly late that we had more than a few graphs of objects that were being loaded upon traversal, leading to a separate mapper triggered SELECT for each object and its children. This is the kind of thing that only becomes apparent when you test with large datasets and get off of your local machine and see some real latency.
And yes, in this case, I think you could argue that QA dropped the ball here. But as a professional software developer you really never want to see issues like this get that far.
I’ve picked one example, but there are many many others in the system I’m referring to. Including but not limited to a proliferation of configuration options and files, heavy conceptual reuse of classes and functionality that are only tangentially related to each other, and an increasing reliance on a “simple” mechanism to do work outside the main code base.
Ultimately, this post has less to do with ORM and proper abstraction and more to do with understanding how your current (and future) developers will react to those decisions. I think a conscious effort has to be paid to how a human will game your system. You need to come up with penalties for doing dumb things if possible, and the path of least resistance for the right ones. There are entire books dedicated to framework and platform development that encompass some of these ideas, but they apply at every level really in my opinion. (except maybe the one man shop?) - Sep 2 2009 - hanselman tools 2009!! ...
Saw this on reddit tonight, hanselman has updates his legendary tools list for 2009. So what was going to be an evening of actual coding is slowing turning into an evening of trying out cool new tools that have made his list. (I’m writing this blog post in windows Live Writer after seeing it in the list)
- Sep 1 2009 - lessons learned from online gambling - predicting scalability ...
I work with someone who has spent a few years working for an online poker company who shall remain nameless. This company was responsible for a poker platform that supported both their own branded poker offering as well as being an engine for other companies who would layer on their branding. My colleague played an important role in taking their fairly well built existing system from thousands of users to tens of thousands of users, and in the process exposing a large handful of very deep bugs, some of which were core design issues.
Looking at this site http://www.pokerlistings.com/texas-holdem and seeing just this small sample of some of the top poker sites is a bit insane. We’re talking close to 100,000 concurrent players at peak hours JUST from the 16 top “texas hold-em” sites listed here. Who are these people? (I’m totally gonna waste some money online one of these days by the way) I’m sure this is just the tip of the iceberg too.
It’s a great domain for learning critical systems in my opinion. Real time, high concurrency, real money, third party integrations for credits and tournaments and the vast reporting that goes on for all that data being generated.
My colleague’s experience in dealing with real time load and breaking the barriers of scalability are truly fascinating and a good source of learning for me. While I realize there are bigger puzzles out there, but it’s not every day you have direct access to that experience where you work. In any case, one such learning that I am in the process of trying to apply is a more forward looking approach to load modeling. That is, rather than to simply design and test for scalability; to actually drill down into the theoretical limit of what you are building in an attempt to predict failure.
This prediction can mean a lot of different things of course, being on a spectrum with something like a vague statement about being IO bound to much more complicated models of actual transactions and usage to enable extrapolating much richer information about those weak points in the system. In at least one case, my boss has taken this to the point where the model of load was expressed as differential equations prior to any code being written at all. Despite my agile leanings I have to say I’m extremely impressed by that. Definitely something I’d throw on my resume. So I’m simultaneously excited and intimidated at the prospect of delving into our relatively new platform that we’re building in the hopes of producing something similar. I definitely see the value in at least the first few iterations of highlighting weak points and patterns and usage. How far I can go from there will be a big question mark.
For now I’ll be starting at http://www.tpc.org/information/benchmarks.asp and then moving into as exhaustive list as I can of the riskiest elements of our system. From there I’ll need to prioritize and find the dimensions that will impact our ability to scale. I expect with each there will be natural next steps to removing the barrier (caching, distributing load, eliminating work, etc) and I hope to be able to put a cost next to each of those.
Simple! - Sep 1 2009 - sometimes it's helpful to think about what NOT to do ...
Came across this list of “anti-patterns” on wikipedia tonight. I’m tempted just to copy and paste the contents here but that would make me feel dirty.
http://en.wikipedia.org/wiki/Anti-pattern
Definitely a good list though and something worth reminding ourselves of every once in a while when thinking about the systems we build. - Jul 22 2009 - performance tuning to an insane level ...
Ok, so I have to admit that I’ve been one to disregard figures around performance when arguing with co-workers over the merit of managed code vs C/C++. I’ve even used the argument that statically typed languages like Java and C# offer more hints to the compiler that allow for optimizations not possible in unmanaged code. I still have a fairly pragmatic view of the spectrum of cost to deliver (skill set/maintainability) vs performance gains… but regardless of all that….. wow this article completely humbled and inspired me.
I don’t know shit.
http://stellar.mit.edu/S/course/6/fa08/6.197/courseMaterial/topics/topic2/lectureNotes/Intro_and_MxM/Intro_and_MxM.pdf - May 8 2009 - Simple Extensibility in .NET ...
I’ve used this approach a few times when I essentially need a really simple plugin / provider model within my applications so I thought I’d jot down the relevant details here for posterity using an old project for adding post commit hooks to subversion.
Consider this a somewhat simplistic approach, not suitable for production code without a bit more plumbing. If you are going all out and need true add-in’s for your .NET based product I recommend checking out the managed add-in framework , very robust stuff and not that hard to implement. In a lot of cases though the isolation, discoverability, communication pipelines etc are a bit overkill. The example I’ll show is a subversion hook that allows for very simple addition of new .NET “actions” to execute on PostCommit. In this case the “add-ins” are only written in house, and editing a config file to hook them up is completely acceptable etc etc.
The solution
Subversion.Contracts : This project is the bridge between our dispatcher and the plugins that will do the work.
Subversion.Plugins : Any of the actions we wish to take post commit are added here, but could just as easily be distributed across as many assemblies and projects as necessary as long as they reference the contracts.
Subversion.Dispatcher : This is the console application that actually receives the arguments from subversion and translates them into our contracts, then executes the appropriate actions (note no references to the plugins project)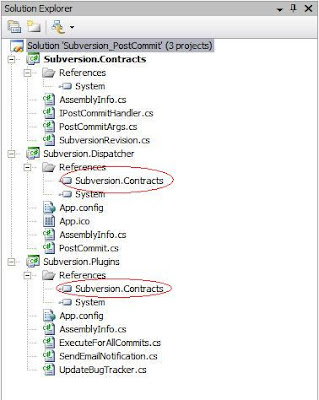
The Contract
The contracts are relatively simple, but whatever you put in them this is the interface for the “plugin” that will need to implement. In our case this is IPostCommitHandler :using System;
namespace Subversion.Contracts
{
public interface IPostCommitHandler
{
void ExecuteCommand(PostCommitArgs a);
}
}
Pretty simple, essentially just a “do whatever you want” method that passes the arguments from subversion wrapped up in a simple class. See the attached zip if you want the guts of the subversion specific stuff.
The Pluginusing System;
using Subversion.Contracts;
namespace Subversion.Plugins
{
public class ExecuteForAllCommits : IPostCommitHandler
{
#region IPostCommitHandler Members
public void ExecuteCommand(PostCommitArgs a)
{
SendEmailNotification.SendEmail(a.Argument, a.Revision);
}
#endregion
}
}
Again, very simple and in this case we’re passing off the execution to a static class that again is not shown, but what gets executed isn’t all that important in this case.. simply fill in what you need.
The Dispatcher (Plugin Host)using System;
using System.Collections;
using System.Text.RegularExpressions;
using System.Configuration;
using Subversion.Contracts;
namespace Subversion.Dispatcher
{
///
///
/// Summary description for PostCommit.
///
class PostCommit
{
private static string subversionPath = ConfigurationSettings.AppSettings[“SubversionPath”];
static void Main(string[] args)
{
SubversionRevision rev = ParseRevision(args);
ArrayList commands = DispatchGlobalCommands(rev);
DispatchNamedCommands(rev, commands);
}
private static SubversionRevision ParseRevision(string[] args)
{
SubversionRevision rev;
if (args.Length == 2)
{
rev = new SubversionRevision(subversionPath, args[0], args[1]);
}
else
{
rev = new SubversionRevision(subversionPath, string.Empty, string.Empty);
}
return rev;
}
private static void DispatchNamedCommands(SubversionRevision rev, ArrayList commands)
{
string[] commitLines = rev.CommitLog.Split(Environment.NewLine[0]);
// Handle Named Commands
string registeredCommands = String.Join("|", (string[])commands.ToArray(typeof(string)));
Regex CommandSearch = new Regex(@"(" + registeredCommands + @")\s*:\s*(.+)?", RegexOptions.IgnoreCase);
foreach (string line in commitLines)
{
string lowerline = line.ToLower();
for (Match Matches = CommandSearch.Match(lowerline); Matches.Success; Matches = Matches.NextMatch())
{
string handlerString = ConfigurationSettings.AppSettings[“command:” + Matches.Groups[1].ToString()];
DispatchCommand(handlerString, Matches.Groups[2].ToString(), rev);
}
}
}
private static ArrayList DispatchGlobalCommands(SubversionRevision rev)
{
// Handle global commands
ArrayList commands = new ArrayList();
for (int i = 0; i < ConfigurationSettings.AppSettings.Count; i++)
{
string key = ConfigurationSettings.AppSettings.GetKey(i);
string val = ConfigurationSettings.AppSettings.Get(i);
string[] cmdParts = key.Split(’:’);
if (cmdParts.Length == 2 && cmdParts[0] == “command”)
{
if (cmdParts[1].StartsWith(""))
{
DispatchCommand(val, cmdParts[1].Substring(cmdParts[1].IndexOf(",") + 1), rev);
}
else
{
commands.Add(cmdParts[1]);
}
}
}
return commands;
}
///
/// Call the appropriate method for the command name given with the argument given
/// no processing of the argument happens here.
///
private static void DispatchCommand(string handlerString, string argument, SubversionRevision rev)
{
// We don’t want properly configured commands to stop working because of errors so trap
// everything here…
try
{
if (handlerString != null && handlerString.Length > 0)
{
string[] typeAndAssembly = handlerString.Split(’,’);
if (typeAndAssembly.Length == 2)
{
System.Reflection.Assembly a = System.Reflection.Assembly.Load(typeAndAssembly[1]);
System.Type t = a.GetType(typeAndAssembly[0], true);
object handler = System.Activator.CreateInstance(t);
if (handler is IPostCommitHandler)
{
((IPostCommitHandler)handler).ExecuteCommand(new PostCommitArgs(argument,rev));
}
}
}
}
catch (Exception)
{ //TODO: log errors
}
}
}
}
There is some plumbing in this class that isn’t directly related to this post, but I’ve left it all anyway. Subversion will run this command every time a checkin is made, and the process ends and starts over again each time. This allows for some pretty simple handling of loaded assemblies and whatnot, if you have a longer running process or are dealing with some scale be cautious. ;-)
The Main function has two jobs, parse and create the revision, then read the application configuration file and start issueing commands for the received revision. Commands are in two parts, those defined in config to be executed always (global commands) and those that are interpreted from the subversion commit log itself, parsed out and executed with arguments from the revision log.
Here are some example commands defined in the config<!– Commands –>
<add key=“command:,chris” value=“Subversion.Plugins.ExecuteForAllCommits,Subversion.Plugins” />
<add key=“command:,check-ins” value=“Subversion.Plugins.ExecuteForAllCommits,Subversion.Plugins” />
<add key=“command:bug” value=“Subversion.Plugins.UpdateBugTracker,Subversion.Plugins” />
<add key=“command:cc” value=“Subversion.Plugins.SendEmailNotification,Subversion.Plugins” />- in the key we have “command:[name]” signifies a command arriving in a revision where somewhere in the revision log we’ll see the command name followed by a colon, anything following the colon is then passed to the plugin as an argument. If the name is an asterisk then we simply execute for all, with an optional argument being passed to the plugin. (so the first example emails chris for all revisions, and the second emails an account named check-ins
- the value portion here is what directs the program where to look for the appropriate plugin and class to execute. I copied the format I found in a web.config file which is to put the class name followed by the assembly name separated by a comma.
In retrospect if I were doing something similar again I’d probably create a better structured format rather than relying on all this string parsing… but old code is what it is in this case.
Finally we call DispatchCommand for each parsed out command which is the last piece of this old code that I’m attempting to document here for reuse. DispatchCommand will read the class name and assembly name, load the assembly name and attempt to instantiate the class/type named in order to call it using our IPostCommitHandler interface.
There are a few ways to do this, and for this project I’m simply calling “System.Reflection.Assembly.Load” which relies on the fact that my plugins are located in my bin directory. I’ve also done this using a “plugin store” which is a fancy way to say I had a dynamic path configured that I could read my assemblies from. In this case you can use LoadFile or LoadFrom, LoadFrom will load dependencies automatically while LoadFile loads just the assembly and will potentially load duplicate copies. (see the documentation) In order to get the dll’s in place for this project we just simply add a post build event like so…copy $(TargetDir).* $(SolutionDir)\Subversion.Dispatcher$(OutDir)
If after instantiating the named type from the loaded assembly we actually have an IPostCommitHandler then make the call! Done.System.Reflection.Assembly a = System.Reflection.Assembly.Load(typeAndAssembly[1]);
System.Type t = a.GetType(typeAndAssembly[0], true);
object handler = System.Activator.CreateInstance(t);
if (handler is IPostCommitHandler)
{
((IPostCommitHandler)handler).ExecuteCommand(new PostCommitArgs(argument,rev));
}
So that’s that. You can download the code here - it should basically work as is if you are looking for a shortcut to extending subversion with .NET. I was relatively lazy with getting this posted - so if you got this far, can use the code, and have problems with it leave a comment and I’ll try to help if I can. - Apr 30 2009 - From test spy to Verify() with Moq ...
Moq is now my favorite unit testing framework for .NET, and a great poster child for the power of the lambda expression support added to C#. If you are not doing unit tests or Test Driven Development you should, and if you already are and have not checked out Moq, you should.
My tests previous to Moq were using NMock, a very handy tool that looks like a lot of other mock frameworks. In order to setup a mock call you would write something similar to this :
[Simple NMock example]Mockery mocks = new Mockery();
IWidgetAdapter mockAdapter = mocks.NewMock();
IListmockWidgets = new List ();
Widget mockWidget = new Widget();
mockWidget.Name = “Mock Widget”;
mockWidgets.Add(mockWidget);
Stub.On(mockAdapter).Method(“LoadWidgets”).WithNoArguments().Will(Return.Value(mockWidgets));
WidgetManager widgetManager = new WidgetManager(mockAdapter);
The ugliest thing in the expression above for me was the literal string that describes the method name that will be called. All of a sudden my fancy refactoring tools don’t quite reach all of my code and things become brittle. Sure you say, but I run these tests all the time! So it is caught right away anyway right? Yeah, but who wants to be searching and replacing these values after every refactor? Just does not feel right.
Here’s the Moq equivelent:
[simple Moq Example]IList
mockWidgets = new List ();
Widget mockWidget = new Widget();
mockWidget.Name = “Mock Widget”;
mockWidgets.Add(mockWidget);
MockmockAdapter = new Mock ();
mockAdapter.Setup(cmd => cmd.LoadWidgets(It.IsAny())).Returns(mockWidgets);
WidgetManager widgetManager = new WidgetManager(mockAdapter.Object);
See that the “LoadWidgets” string disappears, and refactoring code now properly refactors tests right along with it, very very handy. Some find the need to add .Object when referencing the underlying mocked type annoying (on the call to WidgetManager) but personally I find this a small price to pay.
When I first started using Moq a few weeks ago I didn’t go much beyond that example. Which speaks to Moq in that it is VERY easy to get started without much effort and more advanced features really don’t get in the way of the simple features.
For a while I was able to do a lot of the testing I had in place by Asserting on values I either had access to or were being returned to me. In those cases where the values I needed were being returned to someone else (say a Service for example) I was in the habit of building stub classes (Test Spy in this case) to handle the outgoing data.
So using the generic service as an example, and wanting to observe and Assert that I am sending the correct requests to that service my previous code would have looked something like this:
[Test spy example]public class AuthenticationSpy : IAuthenticationService
{
#region Test Helpers
public IListReceivedReqeustContexts = new List ();
public AuthenticationResponse ExpectedResponse { get; set; }
#endregion
public AuthenticationResponse AuthenticateUser(AuthenticationRequest request)
{
return ExpectedResponse;
}
public AuthenticationResponse RenewAuthenticationTicket(RequestContext context)
{
this.ReceivedReqeustContexts.Add(context);
return ExpectedResponse;
}
}
[TestMethod]
public void RenewExpiredTicketTest()
{
AuthenticationSpy _authenticationMock = new AuthenticationSpy();
Mock_respondingMock = new Mock ();
MockmockServices = new Mock ();
mockServices.Setup(cmd => cmd.GetAuthenticationService(It.IsAny())).Returns(_authenticationMock);
mockServices.Setup(cmd => cmd.GetRespondingService(It.IsAny())).Returns(_respondingMock.Object);
ServiceWrapper.Current.ServiceProvider = mockServices.Object;
_authenticationMock.ExpectedResponse = GetGoodAuthenticationResponse(DateTime.UtcNow.Add(ServiceWrapper.Current.TimerSleepTimeSpan.Subtract(TimeSpan.FromMinutes(1))));
// initialize will call authenticate() in the service wrapper
ServiceWrapper.Current.Initialize(“testing”, “Password1”, “http://auth”, “http://resp”);
// now setup and call any method to trigger a renew of our now expired authentication ticket
SetupCreateResponse(Guid.NewGuid());
SurveyController.StartSurvey(new StartSurveyArgs());
// confirm renew was actually called
Assert.IsTrue(_authenticationMock.ReceivedReqeustContexts.Count == 1);
}
This works, and in some cases the control given to you with your test spy can be really helpful, but if I can avoid it I will every time. More classes and more code means more maintenance, even if it is in the test code. So I finally read the docs on the Verify() method on Moq objects and it is awesome. ;-) Here’s the same code handled with Moq properly and without the need for a whole new class imitating the authentication service.
[using Verify example][TestMethod]
public void RenewExpiredTicketTest()
{
Mock_authenticationMock = new Mock ();
Mock_respondingMock = new Mock ();
MockmockServices = new Mock ();
mockServices.Setup(cmd => cmd.GetAuthenticationService(It.IsAny())).Returns(_authenticationMock.Object);
mockServices.Setup(cmd => cmd.GetRespondingService(It.IsAny())).Returns(_respondingMock.Object);
ServiceWrapper.Current.ServiceProvider = mockServices.Object;
_authenticationMock.Setup(cmd => cmd.AuthenticateUser(It.IsAny()))
.Returns(GetGoodAuthenticationResponse(DateTime.UtcNow.Add(ServiceWrapper.Current.TimerSleepTimeSpan.Subtract(TimeSpan.FromMinutes(1)))));
// initialize will call authenticate() in the service wrapper
ServiceWrapper.Current.Initialize(“testing”, “Password1”, “http://auth”, “http://resp”);
// now setup and call any method to trigger a renew of our now expired authentication ticket
SetupCreateResponse(Guid.NewGuid());
SurveyController.StartSurvey(new StartSurveyArgs());
// confirm renew was actually called
_authenticationMock.Verify(cmd => cmd.RenewAuthenticationTicket(It.IsAny()), Times.AtLeastOnce());
}
Check out Part 2 in the 4 part series “Beginning Mocking with Moq 3 ” gives a short description of how Validate works.
Not bad eh? Again the power of the lambda expression here jumps out at you. Full intellisense and compiler support for describing exactly what you expect that method to receive. The “It” class allows for no description “It.IsAny<t>()” or very precise description as above. The “Times” check also allows you to narrow Significant savings in code and maintenance and actually using the testing framework as intended (imagine that) ! My only slight annoyance so far is in having to keep count of the number of times a method has been called in order to check that the last piece of code actually resulted in a call and not some code way earlier. - Mar 25 2009 - silverlight 3 - after the high ...
I failed to convince my manager at work that sending me and a few members of my team to MIX was a worthwhile expense in this economy. So instead I spent a couple days this sprint with http://live.visitmix.com/ on one screen and visual studio in the other. I have to say, Microsoft did an amazing job with MIX in terms of getting me excited and having me “tuned in”. If you are at all interested in web development on the Microsoft stack and haven’t checked out the keynote I’d recommend it. I really enjoyed Buxton’s presentation and Guthrie was amusing.
So now that it’s been a week, and “the Gu” and all those dancing flashy lights are no longer influencing my opinion… I’m STILL excited about Silverlight 3. Sadly the development tools can’t be run in parallel with Silverlight 2 and we’re near the end of our sprint so can’t afford the risk. Which is really too bad because one of the things our current application is leveraging is the wcf duplex polling module. A lovely little COMET like implementation for server push. The version of the duplex polling that made it into the Silverlight 2 toolkit was a little more bare than your typical Microsoft module. And while it works pretty well, it leaves a lot of plumbing code in the hands of the programmer, specifically a lot of asynchronous channel handling code that is a bit of pain to deal with. (though a bit educational too) Anyways, this is one of those areas that Microsoft is improving on in Silverlight 3, and one of those things I’m excited about. Right next to the simpler duplex polling usage for me is the introduction of binary serialization for web services (including duplex!). When comparing to Flex and the myriad of tools and options for using AMF Silverlight was really behind the ball on this one. When we eventually decided to build our tool in Silverlight as opposed to Flex we basically committed ourselves to rolling our own binary serialization. I’m very happy we’re not going to have to follow through on that. Read more from the web services team :
http://blogs.msdn.com/silverlightws/archive/2009/03/20/what-s-new-with-web-services-in-silverlight-3-beta.aspx
Another great addition in the realm of things-that-were-annoying-but-possible-and-already-in-flex is the new navigation uri support within Silverlight 3. Check out Tim Heuer’s typically great post on all the silverlight changes here. (link specifically to the nav)
Lastly to round out my list of really exciting enhancements to SL3 are the network monitoring API, which gives developers events to subscribe to detect when the network is and isn’t present - as well as assembly caching which is huge, allowing Silverlight to cache assemblies like the toolkit so that once a user has been exposed to it they don’t necessarily have to download it again until a new version is required. This in turns makes XAP’s smaller which is always a good thing.
So to summarize, I think the top five features from the slew of enhancements that I’m looking forward to are :- Binary Serialization
- Duplex polling enhancements
- Network detection API
- Assembly Caching
- Navigation and Deep Linking suport
My perspective on Silverlight is very biased to the needs of our application of course. And our application will live and die on the network, with performance being a top concern in everything we do. Controls are nice but we can buy those from vendors like Telerik, animation and media are cool for demos but likely won’t do much for us in the short term. The out of browser story is huge, but again with a SaaS app that relies on the network we don’t envision a whole lot of offline work happening in the early versions of our app.
Honorable mentions for features go to GPU acceleration (performance) and the SaveFileDialog (control) and Expression Blend 3. I don’t use Blend much myself, but the current version is a huge pain for our team. Maybe more on that in a separate post. - Jan 28 2009 - Silverlight controls ...
Silverlight 2 may not have the control set that Flex developers are used to seeing out of the box but there are a significant number of control vendors who are stepping up to the plate to fill the void. It seems as though Microsoft’s strategy has been to get the Silverlight 2 runtime out as quickly as possible (and as lean as possible) always knowing that this type of extension to the framework would exist.
I do still hope to see Microsoft push a little further in controls that are downloaded once and only once with the framework itself thereby making our applications leaner - but it’s a pretty serious tradeoff until the runtime has the kind of penetration that Flash enjoys.
Anyway, here’s a nice post from Tim Heuer that does a good round up of where to find those missing controls.
http://timheuer.com/blog/archive/2009/01/28/comprehensive-list-of-silverlight-controls.aspx - Dec 21 2008 - FlexBuilder 3 First Impressions ...
Where we’re coming from
So at the beginning of the year I was tasked with evaluating a number of technologies for RIA development for the next evolution of my company’s product. Up to this point we had been relying extensively on ASP.NET forms with a traditional post-back model that was responsible for a lot of wasted time and bandwidth. We’ve leveraged a lot of Ajax in the past few years, starting with simple fixes like trees and list based controls that use load on demand and going all the way up to full fledged single page applications that consumed purely services.
This has worked, but the cost is overwhelming for a development team of our size and makeup. We hire smart generalists for the most part, favoring developers with C++/Java/C# backgrounds. Some of our developers have acquired some deeper skills on the client side, but where possible we attempt to leverage control vendors like Telerik and ComponentArt as much as possible. They do an excellent job of hiding some of the complexity involved in cross browser web interfaces, but you will inevitably have to “hit the metal” and get your hands dirty. Relying on third parties also removes a lot of the control needed to do things the way you need them done. Regardless despite being a huge fan of the http://docs.google.com suite of tools, I have witnessed far too much ugliness in our organization with supporting multiple browsers (including having to support IE 6) and pushing the limits of complicated UI in the browser. As the size of the DOM increases and the size of our data sets increase we see wild variance in client performance with respect to things like drag and drop. I know it can be done, I know we are not at the limit yet, but seriously this is not pragmatic for our software and our market and our developers. I am a big fan of the view that JavaScript is becomming the assembly of the web, those who do this shit well, do it well by lifting themselves out of the muck with good abstractions like GWT.
One thing I think should add here in defense of Ajax though; UI design plays a really important role in the effectiveness of the DHTML approach and honestly I believe part of our problem has been designing a far richer interface than we could afford in the technology we were leveraging at the time. Take a close look at Google’s lack of decoration, images etc. These things certainly matter.
Next steps… evaluation
Anyway, I’m getting off topic as usual. In the beginning of 2008 my feature matrix analysis really narrowed our options from about a dozen technologies (including XUL, ActiveX, Applets, JavaFX, Silverlight, ClickOnce, Ajax, Flex) down to three. Silverlight, Flex or Ajax. At the time of my evaluation Flex was at version 2, JavaFX was vapourware and Silverlight2 was in Beta. Given that we are a .NET shop and already have the C# programmers, the Silverlight option was looking like it was going to cleanly win out over Flex. Ajax was honestly only at the table still because we needed to justify our position and show we clearly evaluated all our options. Flex was seen as less desirable due to being based on ECMAScript and having to retool and retrain.
For the most part we’ve seen this as two relatively equivalent technologies with different stories for the developers. While there are important differences between how code is delivered and executed in Flex vs Silverlight, but at a high level we believe technically we can deliver our application in either technology very effectively. We prefer to keep working in C#, but the limited penetration of Silverlight is a serious risk for an application delivered in a SaaS model. That single fact has transformed the whole exercise into largely a business decision. I don’t doubt Microsoft will be able to push their offering significantly, but I would not bet money on where they will be in 1 year. (Windows Media Player STILL doesn’t equal flash in penetration)
Tool support however remains something that is extremely important to developers, and is one of those things Microsoft often trots out in arguing the superiority of their platform. We swallowed that line pretty easily at first, knowing that under the hood all the code written for Flex is just a variation of ECMAScript (JavaScript) is enough to scare us off. How can you acheive the refactorability and tool support provided by current and future versions of Visual Studio with a loosely typed language like ActionScript?
Trying it out
This week I downloaded FlexBuilder3 after one of our senior executives setup a call for us with Adobe evangelists to get more details on why to go with Flex. Again the motivation for this coming back to penetration and wanting to ensure we are making the right decision for what will become a million plus dollar iniitiave to re-engineer. I wanted to get some hands on time with the latest version of FlexBuilder (3) that had come out since our initial research.
I was immediately surprised by the leaps Flex had taken since I last really dived in. I’ll admit there was some bias here though as I am also a huge fan of Eclipse, so the fact that FlexBuilder is built on Eclipse is in my mind a huge win. (not new btw)
The effort in actually building an application that connected to our existing .NET web services was embarrassingly trivial. FlexBuilder has a simple tool for generating and managing proxy classes to represent your web services. So after literally pasting a url into a wizard I had code for talking to our .NET SOAP based web services. (seemed to only support SOAP 1_0 not 1_2) I then got started with the Form Designer and had a simple application talking to our backend in under an hour even counting the little things that tripped me up like where to add my event handlers which wasn’t immediately apparent. (too reliant on double clicking controls apparently ;-) hint : <mx:Script> tags and dom style event callouts)
The concept of states in Flex and the ease with which I was able to create a number of them in the designer and bind those to a dropdown for switching between them was pretty eye opening. A state in Flex is defined by the differences between your main UI (or just another state) and the state you wish to have/be in. The IDE allows you to visually manage these states and then visually modify each one to represent application states. I don’t have an early sense of whether this actually scales for complex applications, but at first glance it’s very cool. (Think hierarchical state machine) Couple this with the data binding model and you have some very effective UI management tools at your disposal. Maybe this only looks cool coming from our antiquated asp.net approaches, but this stuff is exciting. (Silverlight/WPF have the same capability, maybe even a little more advanced but with more overhead in my opinion) Having your model drive all changes is so much more manageable, scalable… and just correct than having explicit assignments in page PreRender methods that set visibility based on the state of that model. Barf.
The control toolkit out of the box with Flex is also extremely impressive. Check out this post for a list of all the FlexBuilder 3 Controls included out of the box . For now at least this control set will mean being highly more productive in the early stages of development than if we were either having to roll our own or rely on third party vendors. And of course you can roll your own in both Silverlight and Flex and each can be just about anything imaginable.
So I’m sold, at least sold on the fact that Flex deserves considerably more attention than what we had previously given it. I’ve bought the “Flex 3 Cookbook”, and “Adobe Flex 3 Training From the Source” and I’m intending on spending at least some of this Christmas holiday catching up on just what’s possible with that silly little flash technology. - Dec 17 2008 - FlexBuilder 3 Controls ...
Controls included with FlexBuilder 3 out of the box below… check out some third party components here .
Notes will be updated as I actually get a chance to put some of these to use.FlexBuilder 3 Controls Control Name Notes AdvancedDataGrid Professional version only
+ multi column sorting
+ grouping
+ tree view
+ printing support
– Still no paging support out of the boxAlertControl not sure how this gets grouped with these other controls as it is not an explicit control but a static method “show()” which can be used from where ever. Button check out the FlexLib CanvasButton for a more flexible option CheckBox ColorPicker ComboBox DataGrid See this article for some hints on implementing paging DateChooser DateField HSlider HorizontalList Image Label List very fast and flexible, lots of issues with scrolling but workable LinkButton NumericStepper 
OLAPDataGrid Professional version only PopUpButton PopUpMenuButton ProgressBar RadioButton RadioButtonGroup Repeater SLOOOW when binding to many objects, look at List based controls instead RichTextEditor Limited html formatting, seems to work ok SWFLoader Text TextArea TextInput TileList see list, very fast control but takes a bit more work for smooth work Tree VSlider VideoDisplay FLV based video player with simple cue and playback control FlexBuilder 3 Chart Controls AreaChart BarChart BubbleChart CandleStickChart ColumnChart HLOCChart Legend LineChart PieChart PlotChart FlexBuilder 3 Navigation Controls Accordion Great control, but needed to go custom almost immediately ( see FlexLib for custom header) ButtonBar LinkBar Menu MenuBar TabBar TabNavigator ToggleButtonBar ViewStack FlexBuilder 3 Layout Controls ApplicationControlBar Canvas ControlBar Form FormHeading Grid HBox HDividedBox HRule ModuleLoader not really a layout control? ModuleLoader allows you to load components of the application on demand, lowering initial download size and improving encapsulation Panel Scrollbar Spacer Tile TitleWindow VBox VDividedBox VRule - Dec 15 2008 - visual c++ lesson 0.0.0.0.1 precompiled headers ...
I come from a background of managed memory and interpreted languages. I’m a big proponent of pragmatic approaches to problems and as little re-inventing of the wheel as humanly possible. I don’t think the world needs another text editor, and I personally don’t feel the need to write my own version of the stack I rely on for application development. (.NET Framework and IIS)
This however gives me less credibility with all those “real” programmers out there. The ones who read assembly for fun and don’t believe in memory management or virtual runtimes/machines. I consistently find myself in battles with control freaks who argue that building an application on top of an application server like Tomcat or IIS is dangerous and excessive when it’s so much simpler to just write your own daemon and connection handling.
Regardless. It is difficult to argue without having credible experience with the alternatives. Not only that, but a number of my dream jobs require extensive C/C++ knowledge (Google) and many important FOSS projects require the same. So I am finally diving in and (re-)learning some C++ with an initial task of writing an XML to ASN.1 converter. (don’t ask why)
I’m doing this in visual studio 2008 with Visual C++, which as I’m learning has it’s own learning associated with it. First is the question of ATL , MFC , WIN32 or just Blank. Visual studio doesn’t give you a whole lot of background on why you might choose one or the other, but some simple wikipedia reading spelled out that for my project I wanted the simplest option. So I went ahead with Win32 Console as it seemed to have the least amount of overhead with easiest start.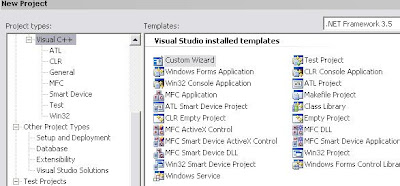 (Why would anyone use the C++ CLR option?)
(Why would anyone use the C++ CLR option?)
From here I moved to some very simple HelloWorld love with some file IO. I’ve taken a course that used C for half of the assignments so I am not completely new to this, but I definitely needed a reminder. Here again I was presented with another option, stdio or iostream ? More wikipedia love, apparently stdio is the old C way of doing things and iostream is the new object oriented way of doing things. There seems to be a lot of contention still about when to use which when, but for my purposes the stream approach seemed more appropriate.
And include how?
#include “iostream”
//OR
#include <iostream>
//OR
#include <iostream.h>
Well visual studio doesn’t allow the last one so that’s easy. Using either of the first two work though works because using the double quotes option will check for an implementation defined location for the file before falling back to the same behavior provided by using the angle brackets. Ok, one more down.
Don’t forget that in Visual C++ adding the above import does not explicitly import the associated namespace. So in order to actually use cin or cout you need to either prefix every instance with std::cin or use the statement “using namespace std;” in order to simply use those identifiers normally.
The next couple hours were learning how to create classes, use namespaces and some simple iterative build up of some basic classes to represent the document I needed to import. Still barely outside the realm of a hello world really.
Now, for this little project I am actually more interested in the ASN part of the problem than I am in the XML parsing so I looked for a parser. I came across the autumn project which references a parser written by Dr. Ir. Frank Vanden Berghen which was appealing as it was relatively small, portable and self contained. You can find the files here.
Now for the fun part. When attempting to compile my newly added class was throwing a dozen or so errors that didn’t exactly make sense to me. I was prepared for some pretty ugly work in trying to port this thing from GCC to the Microsoft compiler, so I didn’t really question these errors. To begin with it was mostly types that were missing. So I would search for the definition of that type and find it in a header file that I was sure was being included. At this point I naively began to move code around in an effort to understand the error. Moving one struct from the header to the cpp file seemed to resolve one error and cause a few more. This seemed to validate my guess that the header was somehow not being included. I had no expectation that this should just work out of the box of course though, so perhaps some of this code was just wrong. I started to chase down the parts of the code that were dependent on flags such as #ifdef WIN32 (I really like how visual studio grays out the code that will not be included based on those conditionals, very nice).
This went on for maybe an hour before I was convinced that this had to be easier. Looking more closely at the build output rather than the error log (which should always be done much sooner than this) revealed this warning :
1>c:\documents and settings\c\my documents\visual studio 2008\projects\xmltoasn\xmltoasn\xmlparser.cpp(82) : warning C4627: ‘#include <Windows.h>’: skipped when looking for precompiled header use
1> Add directive to ‘stdafx.h’ or rebuild precompiled header
This is one of those steps where I know I should have asked more questions when I first started my project. The project by default included my “main” file, but it also included these two stdafx files (header and cpp) which I briefly looked at but didn’t dig into. The comment at the top of stdafx.h shows this :
// stdafx.h : include file for standard system include files,
// or project specific include files that are used frequently, but
// are changed infrequently
Which if you don’t know what pre-compiled headers are may not make a ton of sense. And it sounds to me like this is optional in any case. Well, it isn’t, at least not if you have the build options on your project set to use precompiled headers which by default I did. Simply adding “#include <windows.h>” to the stdafx.h file resolved all the problems. So in fact the xmlParser module WAS portable, and I just didn’t have a clue.
The other way to solve this problem is to actually change the precompiled headers setting for your project to not use precompiled headers at all.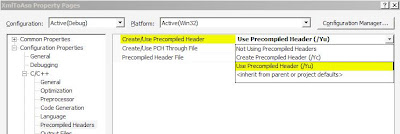
So this was a bit frustrating, but all in all a good first foray into this shit, and I’m at least a few steps closer to having a program that actually does something. - Nov 28 2008 - C++ linking ...
This is a post for myself, to basically bookmark the excellent work of someone else. My post is contributing practically nothing (maybe adding some context/weight for his article) but here it is anyway. ;-)
http://blog.copton.net/articles/linker/index.html
Despite not being an active user of C++ I really enjoyed this post. I actually feel a little smarter and better informed for having read it. Despite the mess in the C++ tool chain being described, this kind of reading actually makes me feel more inclined to dig into this stuff not less. Anyway, filing this one away as something to potentially come back to. - Nov 8 2008 - software fundamentals are exciting? ...
I came across a nice list of fundamental axioms of development on reddit this morning that made me a little pumped. Pumped because I’m in the middle of a big transition at work that in a lot of respects has me starting over with a new team and a new mandate.
I’ll be focusing on solutions, custom work and a view towards short term revenue vs long term research and development for products. Given the economic climate, it’s a shift I can understand and on a personal level one I’m looking forward to. I am saddened of course to be leaving the product I’ve spent the last four years working on, but at the end of the day software is software and this is going to be a big challenge for me.
Here’s the list (http://www2.computer.org/portal/web/buildyourcareer/fa035) highlights for me :EF1. Efficiency is more often a matter of good design than of good coding. So, if a project requires efficiency, efficiency must be considered early in the life cycle.
Q4. Trying to improve one quality attribute often degrades another. For example, attempts to improve efficiency often degrade modifiability.
T1. Most software tool and technique improvements account for about a 5- to 30-percent increase in productivity and quality. But at one time or another, most of these improvements have been claimed by someone to have “order of magnitude” (factor of 10) benefits. Hype is the plague on the house of software.
T1 I believe after having fallen for the tools pitch more than a few times. At the same time though I think one of the differences in the “great programmers are 30 times more efficient than mediocre programmers” comes down to mastery of the tool set. Watch a proficient developer fly through their code and it’s easy to see. On the other hand I’ve seen excellent “users” who fly through a terrible design and become constrained by EF1.
Anyway, for me this is reminscent of the pragmatic programmers list, which as obvious as a lot of it is really made me focus on the core of my craft. See Jeff Atwood’s site for a quick reference if you have not seen this list before :
http://www.codinghorror.com/blog/files/Pragmatic%20Quick%20Reference.htm
While I’m at this, I’ve had some accumulated Martin Fowler wisdom around estimates and scoping that I’ve been meaning to post about. Working in custom solutions will mean writing a lot of proposals and giving fixed cost estimates which is going to be a new game for me…
Martin Fowler: Estimates
http://www.martinfowler.com/bliki/ThrownEstimate.html <– Technical debt, casting quick estimates
http://martinfowler.com/bliki/XpVelocity.html <- Nebulous Units of Time
and on dealing with fixed scope….
http://martinfowler.com/bliki/ScopeLimbering.html <– dragging clients towards a more agile process
http://martinfowler.com/bliki/FixedPrice.html
http://martinfowler.com/bliki/FixedScopeMirage.html - Aug 9 2008 - Regression Ratios ...
Regression is a nasty issue. Ongoing regression from bug fixes can be a pretty clear indicator that there are some serious problems with your code base, your process, your team or all of the above. As an example case consider the effect of moving from 1 in 5 of all bug fixes causing an unrelated issue to crop up to 1 in 10. Given an imaginary scenario where 1000 bugs are found (a medium size project) and a team is closing 20 of those bugs a day then in an extremely simple model we have just added two weeks to our timeline simply from regression issues. (handy chart from google spreadsheets below)
Of course its much more insidious then that though in the real world. For one, regression bugs only pop out at you the minute they are introduced if you’re lucky (they are obvious). More likely is that about half of them will show themselves and the other half will start cropping up near the release date during regression passes. If you alter the model above to show that you’ll see little bulges near the end of the line that start to make time lines feel very elusive and untrustworthy. And given that no QA process is perfect you have to believe that whatever is causing you to introduce those bugs that you are seeing is also causing bugs that are yet to be found.
The importance of quality can never be over-stated, and the effect of poor quality can have a really dramatic impact on a team as well as your customers. Here you are, slaving over your own code, crafting a well thought out and tested solution to a problem, only to have someone else come along and break your code with their fix. Here you are, proudly about to successfully bring a feature out of the QA phase and into the hands of customers and all these elements that you had already seen work are failing. How quickly your trust in your fellow developer begins to wane.
Here though is a problem that I have come to see the light on as being truly systemic. Yes there are horrid developers, and yes there are some difficult technologies, and yes some level of regression is inevitable…. but levels of regression like those that I’ve seen can usually be traced back to process, to your design and architecture, to your requirements and most importantly to your culture.
In terms of process there are some stock answers to bringing this number down like TDD and constant refactoring. I believe in both of these, but in my experience these can be difficult to enfuze into a culture. Without full buy-in and a cultural shift in developers these are just more TLA’s to throw on the steaming pile of buzzwords that will help you magically improve.
Having just come to the end of a release of our product in the past few weeks I am looking forward to whittling away at our own regression ratios.
Changes we’re making :- No more sharing of the bug load. Every developer owns their module/feature/code from design through to maintenance. This include assigning ownership to old modules whose owners may no longer be around. If you write bad code, you will fix more bugs. If you fix more bugs, you will have less time to spend on new bug-ridden features. This will mean our actual bug trends won’t be the pretty descent we’ve worked so hard on achieving. But the overall effect of a self correcting system should help.
- More atomic checkins. Checkins that span branch points, or handling merges of bugs can be extremely error prone with subversion and our current branching strategy. We hope to address this somewhat by eliminating bug fixes that span multiple revisions… Ideally this will involve :
- Patch files attached to the bugtracker for code reviews to avoid multiple checkins when reviews spot errors
- When changes still need to be made to a bug when things are caught in QA then we also revert the original checkin, and checkin again with all changes at once in the new revision.
- Bugs will be closed diligently and new bugs opened rather than morphing the bug over time as new side effects or slightly related bugs are spotted.
- More automated testing. This is last on the list not because it’s least important, but because we don’t expect as quick of an impact as with the other two steps. A major number of the issues we run into remain UI issues. And while WatiN does do wonders for us, it’s painstakingly slow to get the number of tests to where they should be (and keep them up to date).
Lastly just for interest here’s the graph of how we’ve actually done. Black shade are high severity bugs. The first mountain was the release previous where we amalgamated all previous releases into this (migration of existing clients) we had some pretty serious regression in that release after Christmas. The second range is the most recent release which is looking amazing in comparison, though at this resolution you are missing some definite climbs amongst that fall. Definite progress anyway….
- Jul 19 2008 - blogquotes prototype is working ...
I’m supposed to be studying for a challenge exam I’m writing this week in “Advanced” Operating Systems. Instead I spend a good chunk of the day today working on blogquotes in between watching/playing with my daughter.
I can justify this time spent because I did all of this work exclusively from a bash shell using vi to refresh myself on some of the content for the course. In this session I was able to use wget,grep,awk,vi,a shell script and some file permissions. I’m not so sure that will get me through the exam but it was fun and I was finally able to put some time towards my random quote include for the blog.
You can see the quotes being pulled in now in the top right hand corner of this page. So far only my wife and I are using it, as this is very much a proof of concept. It works basically from end to end, but without a lot of features that are going to be necessary as this grows. Paging, searching, caching, tags, some UI polish, and some testing. It’s very gratifying though to reach this first phase and actually get something working. Adding features will probably happen a lot quicker now that I actually have a user. ;-)
I also took the opportunity to try out some of Yahoo’s client side api’s in the YUI. Currently I’m using XHR, Layout and DataTable. I was amazed at how quick it was to basically “assemble” my application. Google’s app engine makes the CRUD a total cake-walk, and yahoo’s user interface library has no dependencies on server side code but works seamlessly with a JSON backed RPC scheme in Python. It’s a whole new world! Now as long as my application doesn’t get popular and I have to start paying for resources. ;-)
Some interesting snags while working on this latest revision:- Randomly selecting an entity in GQL
- Django Utils simplejson can’t serialize google’s db.Model classes, so I had to actually proxy my model class to a simpler structure that I serialize to the client via JSON and XHR
- No unique id’s for google user accounts, all you have is email which isn’t exactly something people are going to appreciate me passing on url’s for the random inclusion widget. The solution was simple for what I needed, a user preference entity keyed on google’s User db type and storing a UUID as the publishingKey, that id now becomes my unique id which won’t change even if you change your google account name
- Google has a very cool AJAX Library SDK for sharing hosting/serving up of all the most popular frameworks like dojo and jquery
- Jul 17 2008 - Microsoft's add-in framework and the need for diligence ... We've recently put Microsoft's managed add-in framework (part of .NET 3.5) into very effective use building a plug-in system for a large asp.net application at work. Essentially the framework in place allows other developers (and our own team for out of stream releases) to develop new functionality for our platform that runs the entire life-cycle for a given widget. In our case for this particular widget we're talking about plugins being responsible for up to 4 asp.net controls in different contexts (for example data collection and reporting as two separate controls) as well as a script injection point where plug-ins are able to extend the scriptability of our platform.For us going with the framework gave us a few things we didn't have with our original design for the add-ins.
- Tools to help enforce the pattern
- An extra layer of versioning over the somewhat naive approach we started with
- Built in discovery, provisioning, and a communication pipeline for serializing types and calls across the contracts that make up the interface between host and plugin
- And last but not least support from Microsoft. This is somewhat more minor than the points above, but it helps legitimize our design when we are following the best practices laid out by Microsoft and used by others in similar situations. The documentation and training available also make getting other developers up to speed on the framework that much easier.
Examples :- Referencing an assembly from both the addin and the host that shared code that should have been passed across the pipeline.
- Bypassing the pipeline completely by calling web services from the addin code (client side or server side calling code)
- Conditional code in the host making decisions based on the type of the addin
- Loose coupling based on common knowledge (that shouldn't be common)
In the case of #1 above the shared assembly started off very benign. Essentially some shared utility code for handling urls and some common resource tasks. Why rewrite when that code already existing the main project? Break it off from the project so that it has no dependencies then drop it in. Except that slowly the terrible pain of building contracts, views and adapters for every little interface or interface change drives you towards shortcuts. "Oh I'll just put this code here to test and then fix it later" Even worse are those cases where you've chosen the path of least resistence in dealing with a bug resulting from unexpected behavior with serialization across the pipeline. It only took a few weeks of not being completely on top of this before I discovered our project was littered with types that were being shared directly between host and addin. Any change meant a recompilation of both projects, completely defeating the purpose.
#2 is a legitimate need in our scenario, and we've found ourselves needing to creating proxy services that wrap our own services just to protect against the inevitable change that will follow. Given that third party developers may be writing code for the platform we have to make an effort to protect from change in all of our interfaces, web service or otherwise. In retrospect I think it would have made more sense to strictly enforce a team division so that no one writing addin code was also writing host code.This probably would have gone a long way to preventing these types of problems.
#3 and #4 are a little more insidious and harder to spot without strict code review. #3 for us isn't technically breaking anything in terms of the interface or future versioning, but adds cruft and generally points to a missing method or property on the interface. The last thing you need as the host is to have case statements littered throughout your code looking for addins. #4 took many forms, and in some cases it's fine. An ok example might be sharing enums, which provided they are defined in the contracts or slightly worse something like a utility class is ok. A not ok example for me was code like this : extension.GetSetting("Menu_Text"); which in this case has two errors. One "GetSetting" shouldn't really exist because how an addin chooses to configure itself should be transparent to the host. Second this code depends on the addin having a value defined in it's config file for the key "Menu_Text". This is next to impossible to enforce and can of course easily break.
Replacing this with extension.MenuText; should be trivial, and a no-brainer. When we started using the framework back in December we were rolling the supporting code by hand. To give you a sense of what this entails, this is how you would define an extension who's only job is to return MenuText as in the code above :
IExtensionContract.csusing System.AddIn.Pipeline;
using System.AddIn.Contract;
namespace SimpleExtensionContracts
{
[AddInContract]
public interface ExtensionContract : IContract
{
string MenuText { get; set; }
}
}
IExtension.csnamespace SimpleExtensionContracts.AddInViews
{
[System.AddIn.Pipeline.AddInBaseAttribute()]
public interface IExtension
{
string MenuText
{
get;
set;
}
}
}
IExtension.csnamespace SimpleExtensionContracts.HostViews
{
public interface IExtension
{
string MenuText
{
get;
set;
}
}
}
IExtensionContractToViewHostAdapter.csnamespace SimpleExtensionContracts.HostSideAdapters
{
[System.AddIn.Pipeline.HostAdapterAttribute()]
public class IExtensionContractToViewHostAdapter : SimpleExtensionContracts.HostViews.IExtension
{
private SimpleExtensionContracts.ExtensionContract _contract;
private System.AddIn.Pipeline.ContractHandle _handle;
static IExtensionContractToViewHostAdapter()
{
}
public IExtensionContractToViewHostAdapter(SimpleExtensionContracts.ExtensionContract contract)
{
_contract = contract;
_handle = new System.AddIn.Pipeline.ContractHandle(contract);
}
public string MenuText
{
get
{
return _contract.MenuText;
}
set
{
_contract.MenuText = value;
}
}
internal SimpleExtensionContracts.ExtensionContract GetSourceContract()
{
return _contract;
}
}
}
IExtensionHostAdapter.csnamespace SimpleExtensionContracts.HostSideAdapters
{
public class IExtensionHostAdapter
{
internal static SimpleExtensionContracts.HostViews.IExtension ContractToViewAdapter(SimpleExtensionContracts.ExtensionContract contract)
{
if (((System.Runtime.Remoting.RemotingServices.IsObjectOutOfAppDomain(contract) != true)
&& contract.GetType().Equals(typeof(IExtensionViewToContractHostAdapter))))
{
return ((IExtensionViewToContractHostAdapter)(contract)).GetSourceView();
}
else
{
return new IExtensionContractToViewHostAdapter(contract);
}
}
internal static SimpleExtensionContracts.ExtensionContract ViewToContractAdapter(SimpleExtensionContracts.HostViews.IExtension view)
{
if (view.GetType().Equals(typeof(IExtensionContractToViewHostAdapter)))
{
return ((IExtensionContractToViewHostAdapter)(view)).GetSourceContract();
}
else
{
return new IExtensionViewToContractHostAdapter(view);
}
}
}
}
IExtensionViewToContractHostAdapter.csnamespace SimpleExtensionContracts.HostSideAdapters
{
public class IExtensionViewToContractHostAdapter : System.AddIn.Pipeline.ContractBase, SimpleExtensionContracts.ExtensionContract
{
private SimpleExtensionContracts.HostViews.IExtension _view;
public IExtensionViewToContractHostAdapter(SimpleExtensionContracts.HostViews.IExtension view)
{
_view = view;
}
public string MenuText
{
get
{
return _view.MenuText;
}
set
{
_view.MenuText = value;
}
}
internal SimpleExtensionContracts.HostViews.IExtension GetSourceView()
{
return _view;
}
}
}
IExtensionAddInAdapter.csnamespace SimpleExtensionContracts.AddInSideAdapters
{
public class IExtensionAddInAdapter
{
internal static SimpleExtensionContracts.AddInViews.IExtension ContractToViewAdapter(SimpleExtensionContracts.ExtensionContract contract)
{
if (((System.Runtime.Remoting.RemotingServices.IsObjectOutOfAppDomain(contract) != true)
&& contract.GetType().Equals(typeof(IExtensionViewToContractAddInAdapter))))
{
return ((IExtensionViewToContractAddInAdapter)(contract)).GetSourceView();
}
else
{
return new IExtensionContractToViewAddInAdapter(contract);
}
}
internal static SimpleExtensionContracts.ExtensionContract ViewToContractAdapter(SimpleExtensionContracts.AddInViews.IExtension view)
{
if (view.GetType().Equals(typeof(IExtensionContractToViewAddInAdapter)))
{
return ((IExtensionContractToViewAddInAdapter)(view)).GetSourceContract();
}
else
{
return new IExtensionViewToContractAddInAdapter(view);
}
}
}
}
IExtensionContractToViewAddInAdapter.csnamespace SimpleExtensionContracts.AddInSideAdapters
{
public class IExtensionContractToViewAddInAdapter : SimpleExtensionContracts.AddInViews.IExtension
{
private SimpleExtensionContracts.ExtensionContract _contract;
private System.AddIn.Pipeline.ContractHandle _handle;
static IExtensionContractToViewAddInAdapter()
{
}
public IExtensionContractToViewAddInAdapter(SimpleExtensionContracts.ExtensionContract contract)
{
_contract = contract;
_handle = new System.AddIn.Pipeline.ContractHandle(contract);
}
public string MenuText
{
get
{
return _contract.MenuText;
}
set
{
_contract.MenuText = value;
}
}
internal SimpleExtensionContracts.ExtensionContract GetSourceContract()
{
return _contract;
}
}
}
IExtensionViewToContractAddInAdapter.csnamespace SimpleExtensionContracts.AddInSideAdapters
{
[System.AddIn.Pipeline.AddInAdapterAttribute()]
public class IExtensionViewToContractAddInAdapter : System.AddIn.Pipeline.ContractBase, SimpleExtensionContracts.ExtensionContract
{
private SimpleExtensionContracts.AddInViews.IExtension _view;
public IExtensionViewToContractAddInAdapter(SimpleExtensionContracts.AddInViews.IExtension view)
{
_view = view;
}
public string MenuText
{
get
{
return _view.MenuText;
}
set
{
_view.MenuText = value;
}
}
internal SimpleExtensionContracts.AddInViews.IExtension GetSourceView()
{
return _view;
}
}
}Yeah, seriously. One interface and one string accessor requires nine class/interfaces and over 200 lines of code (which obviously could be made less with formatting etc). It's also possible to share the views between addin and host but then you lose part of the more compelling robustness of the framework. If you are interested in where these classes come into play and how the add-in framework actually works check out this link for a good description.Anyway, I can sympathize with the developers in wanting to speed up the process a bit, but the answer is not to bypass the pipeline. The answer is code generation! Thankfully by the time we realized our mistake Microsoft had released a CTP of their pipeline generator which is a nifty little visual studio addin which picks up the output of the Contracts project and uses reflection to find all of the contracts and generate the necessary projects and files for the pipeline. It literally saved us tons of hours and made the addin framework actually usable. Of couse the code generation is only going to work until we version one side or the other, but at that point we should have solidified those interfaces considerably so it will matter a lot less.
Anyway, long story short, the add-in framework is great, but it's really important for the entire team to understand the goal and be diligent in ensuring that all that extra framework code isn't just being wasted by introducing dependencies. - Jun 26 2008 - Enough rope to hang yourself (C# Extension Methods) ...
So I ran into an interesting “gotchya” with C# extension methods tonight. And of course it happens at the 11th hour on a project that is being demoed at 9:00am tomorrow morning. Of course.
Extension Methods
Extension methods are a really cool new feature of C# that were introduced in version 3.0 of the language. Essentially they are static methods that act like instance methods, allowing you to extend objects you don’t own. Ok, seeing those words on screen makes me think this is a terrible idea, but it really does have it’s place. (LINQ relies heavily on it)
When I first saw these I got quite excited because we had a number of scenarios where they would make our code much much cleaner and easier to maintain. I can name a couple examples in our own project where this has the potential to make the API cleaner.Example 1: Helper/Utility/Static Methods
Try as they might, the .NET framework guys will not anticipate every piece of code that ends up repeated hundreds of times across your project to get around a common case. Before the framework added String.IsNullOrEmpty() in 2.0 we had StringHelper.IsNullOrEmpty(string arg)in our code base along with about half a dozen other methods. Now string may not be the best example, because in my mind I think it’s a bad idea to write extensions to framework types, but it does illustrate the problem well.
In our project we have maybe a dozen of these Helper classes full of static methods (utility pattern). They are useful, but the biggest problem is the team’s ability to consistently discover those methods. Emails and other forms of communication helps, code review helps but ultimately you end up with repeated code fragments where helpers could have been used or even worse you end up with competing helpers in different namespaces that need to be consolidated once discovered.Example 2: Enhancing Functionality Based on Context
Another useful place for extension methods in our project is to have our domain model be extended differently based on the area of the application and what rights the users executing that code have. Essentially what we have is two sets of functionality that are implemented very differently based on the context. For example in one context our object model is mapped using an ORM to the database directly, where as in another context that same object model is used with pre-populated data sets that are cached and completely scriptable by our end users. We still have code that needs to understand these objects across this context however, leading us to create interfaces for every single object in that domain that needs to work across these two contexts. I’m a fan of interfaces, but I think in this scenario we’ve clearly lost something in terms of the DRY principle and code readability.
I’ve yet to really map out what this will look like for our project, but I see what’s been done with Linq and am excited about how simple it could be for example to include the “.Scripting” namespace to attach methods to our domain model that are exposed to end users. Similarly an “.API” namespace for our internal privileged code base with everyone sharing the same core objects.The Gotchya that kept me at work an extra hour
Symptoms- Your extension method is no longer ever being executed
- Intellisense shows the correct method signature, reports no problems
- Right click “go to definition” takes you to the method you think will be hit
- Stepping through the code shows you never reach your extension method
I’ve created some fake code to illustrate the problem. Imagine we have a simple factory class providing some useful functions like so :namespace ExtensionMethodsTest
{
public class FactoryA
{
public ObjectA GetInstance()
{
return new ObjectA(“empty object”, -1);
}
public ObjectA GetInstance(string name)
{
return new ObjectA(name, 0);
}
}
}
But then we decide that we actually need to grab instances of ObjectA using an int id, so we add that using an extension method like so :using ExtensionMethodsTest;
namespace MyExtendingNamespace
{
// a container for my extensions
public static class ExtendFactoryA
{
// Extend our factory to look objects up by id
public static ObjectA GetInstance(this FactoryA factory, int id)
{
return new ObjectA(“got by id”, id);
}
}
}
Blamo! Now anytime we’re using the “MyExtendingNamespace” our FactoryA includes the third way to grab an instance of ObjectA.
Here is how I am calling both of these :private void ByIdButton_Click(object sender, EventArgs e)
{
FactoryA fa = new FactoryA();
ObjectA a = fa.GetInstance(42); // call extension method with int
this.label1.Text = a.ToString();
}
private void ByNameButton_Click(object sender, EventArgs e)
{
FactoryA fa = new FactoryA();
ObjectA a = fa.GetInstance(“gotten by name”); // call instance method with string
this.label1.Text = a.ToString();
}
This seems ok, our calls to GetInstance are consistent and we have everything working. Now transplant yourself a couple months into the future when the original owner of the FactoryA class has a need to alter the behavior to allow for more scenarios for retrieving instances of ObjectA.public ObjectA GetInstance(object proxyObj)
{
return new ObjectA(proxyObj.GetType().Name, 0);
}
Now from the calling code everything still appears to work fine, intellisense continues to show the “int” signature that you think you are calling, and in fact if you right click the GetInstance call and say “Go to Definition” it takes you to the MyExtendingNamespace version of GetInstance.
At runtime however the CLR looks first for something that matches your call to fa.GetInstance(42); within the main namespace/class before looking at any extensions. Because our int gets automatically boxed we actually match “object proxyObject” and will never reach the extension method. Depending on the specific implementation in your code this can be a particularly insidious error or it may fail outright. Either way on a large project it can be a real annoyance to track down.
To me there are a few mistakes here. 1) Why use an extension method here at all? 2) In general I think extension methods as overrides make little sense given how the CLR matches these and 3) GetInstance(object proxyObject) should probably be something more specific like ProxyBase or something else that is not an object. (Akin to catching System.Exception, bad… be specific)
Fixing this issue is as simple as renaming the extension method to GetInstanceById, or moving the method onto the Factory itself, or fixing the factory method to not use object. Personally I say drop the extension method.
My example is over simplified, and in our scenario at work there was a little more justification for not changing the class that defined the original functionality. To me though this seems like the tip of an iceberg of problems.- Why negotiate with a module maintainer when I can just add functionality right here right now from my own code?
- Why stop to understand that class and how it’s been constructed when I can just impose my view of how it should work overtop?
- Intellisense makes it easy to find the method, so I don’t have to worry about how I organize this code.
Terrifying. - Jun 21 2008 - here here - use var sparingly ...
When I first read Jeff Atwood’s latest post on his love of C#’s new “var” keyword I was deeply bothered that my co-workers would find the article and latch on to the argument as a justification for laziness. While I do understand his point of view I was bothered by the idea of var statements littered throughout the code base making things more difficult to read for the next developer.
Saving key strokes is never justification for obscuring the code base. If you want to save keystrokes improve your environment, don’t sacrifice your code.
I came across this post on reddit tonight that very nicely counter’s the post on coding horror. Thanks Richard for a voice of reason.
http://richarddingwall.name/2008/06/21/csharps-var- keyword-jeff-atwood-gets-it-all-wrong - Jun 14 2008 - Dynamic vs Static... no wait make that DBC! ...
I need to blog this basically to toss it in my archive. There have been some interesting posts on the religious debate of static vs dynamic languages. I don’t know why I always get drawn into these lines of thought, but I do. (in fact I just added a “versus” label)
I say drawn in because my underlying philosophy in all of these things is to choose the right tool for the job and leave it at that. I know, hardly original thinking, but despite the mantra and the collective nod that this is true we still get very heated on issues that are not actually at odds with each other.I’m NOT arguing that with you. I’m not arguing that with YOU. I’m not ARGUING that with you. I’m not ARGUING that with you Harry! Harry… Harry… Yeah Harry… but can he DO the job. I know he can GET the job but can he do the job?
Still there is fun to be had in the whole exercise. For the record I tend towards the static languages. Despite my recent fun with Python I have spent the last four years neck deep in C# and really am loving it. Our application uses over 75,000 lines of JavaScript, and every opportunity I have to decrease that number I will take. (Part of my excitement about Silverlight is just not having to write as much JavaScript anymore) I see the power in dynamic, I’ve done some really cool things with JavaScript and I’ve really enjoyed working in Python again…. but I believe there is less of a ceiling for static languages then there is for dynamic in terms of tool set, performance and the ability to handle large projects with large teams.Mr. Waturi, Joe vs the Volcano
Anyway, Mat Podwsocki presents a great summary of the debate with links to a few bloggers here :
http://codebetter.com/blogs/matthew.podwysocki/archive/2008/05/28/static-versus-dynamic-languages-attack-of-the-clones.aspx
The original Steve Yegge presentation is here :
http://steve-yegge.blogspot.com/2008/05/dynamic-languages-strike-back.html
And the response that I enjoyed the most is here :
http://codebetter.com/blogs/gregyoung/archive/2008/05/18/revenge-of-the-statically-typed-languages.aspx
I enjoyed Greg’s response because it just really got me thinking. I honestly know nothing about the design by contract research that’s going on, but it just feels like something that makes sense. I got excited just imagining seeing errors like the ones described showing up in our project at compile time. I believe that if we were using such a system we would see a real improvement in quality. I can see how some would see this as an unnecessary burden on the developer, but these are probably the same crowd not writing their unit tests.
Design by contract is really a great example of what I mean when I’m thinking about the potential for statically typed languages in tool sets. - Jun 10 2008 - Google's changing the rules again (appspot) ...
I am super excited about Google’s recent foray into cloud computing, the app engine. They are not first, I realize Amazon has been doing some pretty cool things with the S3 services and their computing services but the ability to simply and easily have an application that can leverage BigTable and GQL, google account authentication, image manipulation, memcache and having that all live within the seemingly infinite scalability of the google platform is extremely exciting for me. In fact it’s the whole reason for my recent resurgent interest in python. App engine out of the gate is a python runtime environment which is robust enough even to run frameworks like Django for your web apps.
ArsTechnica had some good comments on the service and one of their cheif concerns was being locked into the platform. I think this is not an invalid concern, but that the tools will be written to make migration from one platform to another a relatively trivial matter. From what I understand of GQL it is a subset of normal SQL with limitations like no joins which should make data/code migration easy, but scalability and hosting maybe not so much. There are open source implementations such as HyperTable which is modeled after Google’s data platform, but ultimately the article is right. Personally I don’t see myself writing large scale applications on this platform though, I see this much more as a utility model for small useful services.
I registered for the preview of app engine on the same day it was announced but not early enough to be one of the lucky first 10,000. When I did get my invite a couple weeks ago I immediately started to create applications. It’s clear this is exactly what everyone else did and I’m glad Google has capped usage at three applications per developer. Already it’s almost as bad as trying to register a domain. For each of my three applications I had to try a series of names before getting a clear one. In other words none of my ideas are at all unique. :-) On a positive note when I checked the names I was looking for there were also no uploaded applications for any of them. I predict Google may have to have an expiry date on these - I can see myself taking weeks or months to finally get anything uploaded.
http://silitrader.appspot.com (silverlight port of the old game OilBaron)
http://wherediditallgo.appspot.com (personal spending tracker)
http://blogquotes.appspot.com
I actually created that last application as I was trying to find a simple means of having a rotating list of hand picked quotes show up in the header of my blog. Back when somatose.com was hosted with LunarPages this would have been trivial, throw the quotes into a textfile, write a script to randomly choose and insert one as I was building the page. I moved from a hosted environment to using blogger so that I would stop tinkering and focus on actual content. I spent most of tonight tinkering though, building up to actually building blogquotes. (By the way I am sure there are other blog quote like tools out there, but this is a rare case where I don’t mind reinventing the wheel somewhat)
Now the nature of the tinkering has just changed. Rather than write a small shell script that spits out random lines I will actually build something of a small application/service. The quotes will be stored using the datastore api (GQL), and will be publicly visible. Other users will be able to authenticate and store their quotes in a similar manner. A widget will be built and hosted from that application that enables anyone to paste in a snippet of html to add random quotes from their personal db. I as a user can subscribe to my friend’s quotes. It’s remarkable really, the differences and yet familiarity of this new ecosystem. And while I do miss the control of simply writing a little shell script I have to say I love the idea of the internet being populated by these little widgets of functionality. The emergence of ajax and increasing power on the client means that millions of non-technical users who blog on platforms like blogger and wordpress can very easily use my quote engine. How cool is that?
Google’s API’s (and Amazon’s) are proving to be the next Win32. Massively widespread and base functionality that anyone can build on. The plumbing is there for us to be able to chain together these small tools/widgets in much the same way a clever unix user could within their shell. And once the honeymoon wears off and I actually give some though to hosting data in the US and dealing with popularity should one of my apps get hammered and I end up having to pay Google usage fees… well until all those little issues I can just be excited again about the changing landscape. - Jun 7 2008 - Do I really need to embrace C++? ...
My internal debate rages on… I have some C++ courses in the pipeline so I will definitely learn more than the basic understanding/grasp I have now…
Still though. Currently I associate C++ proponents with old-school attitudes on the need for absolute control and a fear of newer levels of abstraction that are allowing increasing complex and large projects. Garbage collection, the .NET framework etc, are all grouped together into a category of tools that only “weak” programmers need. I recoil pretty hard from this line of thinking and associate it with a dangerous cowboy like attitude towards engineering.
There is a lure there, to join the elite, to be one of those cowboys who don’t need frameworks or garbage collection and who’s code can scream past yours with sheer force of will by the programmer. So I’m constantly torn between mockery and envy. I will say that I think it’s important to learn and think in C++ because the deeper our understanding of the systems we develop for the better off we are. I’d say the same thing about assembly though and would be just inclined to write large systems in C++ as I would in assembly.
My own line of thinking is that these abstraction layers we’ve invented are more akin to compilers and file systems and OS API’s. Why should we all re-invent the wheel (and poorly) when these problems can be solved in a generic way?
Anyway C/C++ are probably not going anywhere and have their niche, but I thought I would post this article to preserve it in my memory bank.
http://www.mistybeach.com/articles/WhyIDontLikeCPlusPlusForLargeProjects.html - May 13 2008 - Javascript session hacking ... I had to blog this, and yeah I'm going to be the billionth person to do so, but that's ok because no one reads my blog and it's basically just my personal public archive. (ppa?)This guy http://www.thomasfrank.se/sessionvars.html has managed to find a very clever place to store data within the browser without resorting to cookies, flash or anything beyond basic cross browser javascript. Apparently "window.name" which lost it's usefulness when the spammers started making popups obsolete can contain arbitrarily long strings that persist as long as that window is open (equivalent to a session cookie)This is damn cool, and while a part of me twinges at the hack-ish nature of overloading a window property with a bunch of json strings, well this is javascript we're talking about here so what the hell. You're already standing out in the rain trying to build a fire with soggy sticks and no pants so why not use what you've been given.This is just one of those things I know I'll want to come back to one day for one of my pet projects so I thought I'd blog it.
- May 11 2008 - ASP.NET Ajax Pendulum ...
I’m currently working on moving a web application from using some ad-hoc javascript and iframes to a full fledged ASP.NET Ajax implementation based around Telerik’s RadControls and a suite of our own controls. This is the third application we’ve given the ajax treatment to and each time we’ve taken a slightly different approach.
Approach 1 … “Javascript + Web Services”- Full view manager/page controller implementation on the client side to handle events thrown by all the components on the page
- Homegrown “ServiceManager” to handle brokering calls to the server
- Centralized error handling
- Shared message contract base class to allow “sub-messaging” for the server to send information to the view controller on the client
- Blocking calls when things needed to be “modal” or serialized
- … we had intentions of also building in grouping of calls
- … we had intentions of canceling redundant calls when the user was asking for something that made a previous call unnecessary
- Centralized error handling
- Chatty - many calls, small amounts of data (largely json)
- Javascript controls that render almost strictly client side based on data delivered over web services
- Zero postbacks / Very fast
- Expensive/Complex development and maintenance
- Prone to memory leaks
- More difficult to leverage third party controls
Approach 2 … “Update Panels”- Traditional ASP.NET development with a sprinkling of update panels where it made sense
- Chunky communication… partial postbacks, but still heavy
- “Simple” development - UpdatePanels were spotty at the time, there were quite a few workarounds hacked in to this interface
- Medium reliance on third party controls
- Less performance than “Javascript + Webservices”
- Less transparency and control to developers
Approach 3 … “Javascript + Web Services + Update Panels”- A view controller/ page manager approach similar to Approach 1 except that in this iteration we are relying on the ScriptManager and it’s events to handle a lot of what we were previously rolling on our own.
- A heavy usage of Telerik’s Prometheus suite of controls, which in turn is built against the Microsoft Ajax Framework
- Webservice layer for a class of managed actions where we control the control flow via our view controller
- Partial updates for more complex control interactions/workflows
- These are sometimes triggered by the controls themselves in which case we are dealing with “chunky” transactions
- Othertimes triggered by the page manager in which case we have small requests and potentially heavy responses
- Good use of third party controls
- Chunky or Chatty based on need
- Medium development complexity
- Less transparency/control for developers
- High development complexity
- Better performance than Approach 2) but less than 1)
- Still prone to memory leaks
So you can see across these three different applications we’re dealing with a swinging pendulum of ajax development methodologies and philosophies. My hope with our most recent approach was that we would have the strength of increased reliance on Microsoft’s framework + Telerik’s suite of controls combined with hooks and web services to eek out that extra level of performance whenever needed.Of course in this latest iteration we also have the added complexity of having to port legacy controls on a very difficult timeline. So we have a collection of editors, some of which are doing chunky partial post-backs whereas some of our newer type editors are using a more… let’s say finely tuned approach where only the necessary data is sent and only limited page updates are performed.The third option still has some proving out to do. Rather then being the perfect blend of complexity vs performance vs reuse vs transparency is instead turning out to be not especially good at any of these. I’m frankly a bit frustrated by the whole exercise right now an am increasingly eyeing the glorious promises of Silverlight.Really I don’t see this stuff getting any easier until we’re either seeing browsers that have equivalent capabilities in supporting Html 5 and all the exciting new javascript features of the future or a widespread installed base of Silverlight 2. haha… right.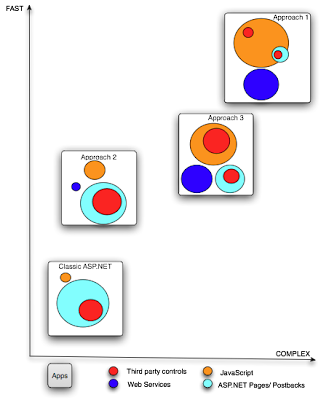
- May 5 2008 - I've forgotten how much I enjoy Unix ...
I just finished reading “The Dream Machine” and getting a very cool look at some early history of computing including the birth of Multics and it’s spin off and almost more interesting the birth of tools like email and ftp as a way to actually do something with the ARPANET that was being built. A great read for anyone interested in how we collectively have arrived at where we are today in computing. And as it happens, I’m also currently challenging a course on Unix which as part of the challenge requires that I complete a project before I can write the final exam.
The project itself is great fun actually. I’ve been in the world of Microsoft for so long at work that I’ve completely forgotten about the old days of living in vi on Solaris as part of my 9-5 work. (CATI programming back then) More than anything about Unix I love the power and flexibility of combining these small well written tools like awk, sed, grep etc. These are incredible tools and it’s easy to forget how powerful a fully text driven system really is.I remember being completely stoked about Microsoft’s powershell project a few years ago. On the surface it seemed to take everything exciting about a Unix environment and add a layer of object orientation across it so that not only could you fully embracing piping and redirection with the help of some impressive shell programming capabilities but you also had the full .net framework at your fingertips and the ability to use reflection to “discover” a system at run time. This discover-ability aspect is key, and the importance of “man” to rusty or newbie Unix users can let you appreciate the value in being able to query objects to ask what they can do. The simplest example of where powershell is so powerful is to just imagine good ole ls, but where each element output from ls was an actual file or directory object. If you do nothing then those are simply iterated by ls and essentially .FileName.ToString() gets called for each… but if you pipe that output to your own iterator you can all of a sudden do some really amazing things with very little effort.Having said that though I never truly fell into powershell like I have unix in the past. In my opinion it’s about the eco-system. The set of utilities in unix work because everything in unix plain old text, meaning the same tools can be strung together to do any countless numbers of tasks without additional support. Compare this to powershell which really loses it’s value where .NET doesn’t exist. True, there are some amazing providers that bridge gaps into SQL Server, WMI, etc etc. But just the fact that you are now talking about .NET development to create those new bridges means we’re half a step behind the accessibility and simplicity of a text file. I do think that powershell will only get better with age, but for now unix as a whole is still king for me even if powershell is sexier.Anyway, this project I’m working on is just a series of clever questions that force you to construct chains of tools to elegantly (or inelegantly) solve a problem. It’s extremely fun and in the course of a couple weeks I’ve reinstalled cygwin at work, gotten ssh access to my mac at home and have had terminal open for pretty much a week straight on my iMac. It’s hard to keep this up without an actual task - and considering I’m still doing 95% .NET development i don’t expect this will continue for too long but it’s a good reminder. - Apr 30 2008 - Patches on a centralized VCS in a small team ... My team is always looking for ways to improve on quality and one of the proposed ideas this year was to follow a model similar to large open source projects where basically every checkin is first proposed as a diff/patch and then vetted into the code base AFTER review.
Our current setup is a single large subversion repository where our team (~14 developers) all checkout the entire mainline branch we're working on and make commits to mainline as desired. Bugfixes are typically checked into mainline, then merged as requested by QA into the appropriate build. Once checked in the bug is updated in our bugtracker and handed over to another developer for code review.
But of course, the code is now already checked in, and we're in a state of flux until the second developer gets around to reviewing the code. If problems are found (more often than you might expect) then subsequent checkins are made and not only is mainline in a state of flux (what happens if QA branches here?) but we also have lost the nice clean atomic nature of a single checkin. Merges get harder and tracking the code associated with a bug is just a tiny bit more overhead.
I also believe that knowing a checkin has already been committed does something mentally to the reviewer. It's no longer as easy to request changes that might seem superficial or strictly style based. In the back of your mind as the reviewer you know that your comments will introduce a messy string of commits that you unconsciously weigh against the importance of your review.
Our QA lead has often suggested a solution to this problem where code reviews must be done in person and before the checkin. As much as I can see the improvement this would have on quality I personally have issues with the frequent interruptions and delays this would add to the process. Not to mention the challenge of working from home and/or late. Not a good idea.
So patches it is. I managed to convince my team leads that this was worthy of an experiment and so we chose three people out of a hat and for two weeks it was patches and only patches for all bug fixes. For those two weeks we would use TortoiseSVN to create patches of our changes and attach those patches to bugs in BugTracker. A reviewer would examine the diff rather than a subversion commit log and the process would repeat until the developer got it right.
I liked the process, but overall it just didn't really fly with the test group. Here are a sampling of some of the reasons :- Complexity in managing multiple ongoing bugs at once
- Reviewing via diff lacked enough context, whereas reviewing a subversion log using TortoiseSVN actually let you see the entire files with highlighted differences
- Adding binary files seemingly couldn't be done in a patch (rare but annoying)
- Extra steps required are often slow on our repository because of size
What's interesting is that in retrospect I am having a hard time seeing what the real issue here was. I believe that with diff being as standard as it is and the tool support available out there that almost all of these issues can be solved with some infrastructure and automation around the process. As it is the resistance to the idea and my unwillingness to force unnecessary process has killed this effort for now.
Given the size of our team and the fact we are all working with fast direct access to subversion it's hard to justify needing to work with patch files. Particularly since "revert changes from this revision" is so easy to do.
I do think this is one of those things worth pushing again, I may just have to do the legwork to smooth the process and prove the utility before getting everyone on board. - Mar 30 2008 - On the need for re-architecting ...

I have been grappling with the concept of a rewrite of a relatively successful software product that I’ve been involved with since start-up mode. In truth I was googling for compelling stories about why NOT to disappear for a year to do a complete re-engineering of your product (ala Netscape). Mostly because I’m concerned about the size of the effort and the resources we have to pull it off. Instead came across this article, espousing the need to fire all your developers!
http://mikemason.ca/blog/?p=19
Well I’m the guy who’s been promoted to a more senior developer role (not architect, our group shares that responsibility) but still by Mike’s logic the guy who should be fired (?!). I’m the guy who now is learning the ropes in management and who happens to really know the product and the business but now swimming in very exciting waters when it comes to our rearchitecting plans.
What I do have going for me is an incredibly strong team to work with. I’m undecided yet as to whether we actually need an ivory tower architect or if our guys can work this with the guidance of our CTO. We’ll see, as it’s still not too late to change course.
In any case I think I’ll keep an eye on more perspectives like Mike’s…