Controls included with FlexBuilder 3 out of the box below… check out some third party components here .
Notes will be updated as I actually get a chance to put some of these to use.
I come from a background of managed memory and interpreted languages. I’m a big proponent of pragmatic approaches to problems and as little re-inventing of the wheel as humanly possible. I don’t think the world needs another text editor, and I personally don’t feel the need to write my own version of the stack I rely on for application development. (.NET Framework and IIS)
This however gives me less credibility with all those “real” programmers out there. The ones who read assembly for fun and don’t believe in memory management or virtual runtimes/machines. I consistently find myself in battles with control freaks who argue that building an application on top of an application server like Tomcat or IIS is dangerous and excessive when it’s so much simpler to just write your own daemon and connection handling.
Regardless. It is difficult to argue without having credible experience with the alternatives. Not only that, but a number of my dream jobs require extensive C/C++ knowledge (Google) and many important FOSS projects require the same. So I am finally diving in and (re-)learning some C++ with an initial task of writing an XML to ASN.1 converter. (don’t ask why)
I’m doing this in visual studio 2008 with Visual C++, which as I’m learning has it’s own learning associated with it. First is the question of ATL , MFC , WIN32 or just Blank. Visual studio doesn’t give you a whole lot of background on why you might choose one or the other, but some simple wikipedia reading spelled out that for my project I wanted the simplest option. So I went ahead with Win32 Console as it seemed to have the least amount of overhead with easiest start.
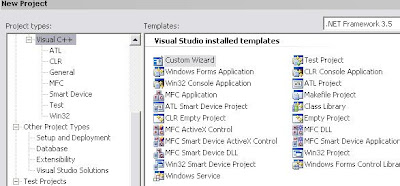
(Why would anyone use the C++ CLR option?)
From here I moved to some very simple HelloWorld love with some file IO. I’ve taken a course that used C for half of the assignments so I am not completely new to this, but I definitely needed a reminder. Here again I was presented with another option,
stdio or
iostream ? More wikipedia love, apparently stdio is the old C way of doing things and iostream is the new object oriented way of doing things. There seems to be a lot of contention still about when to use which when, but for my purposes the stream approach seemed more appropriate.
And include how?
#include “iostream”//OR#include <iostream>//OR#include <iostream.h>Well visual studio doesn’t allow the last one so that’s easy. Using either of the first two work though works because using the double quotes option will check for an implementation defined location for the file before falling back to the same behavior provided by using the angle brackets. Ok, one more down.
Don’t forget that in Visual C++ adding the above import does not explicitly import the associated namespace. So in order to actually use cin or cout you need to either prefix every instance with std::cin or use the statement “
using namespace std;” in order to simply use those identifiers normally.
The next couple hours were learning how to create classes, use namespaces and some simple iterative build up of some basic classes to represent the document I needed to import. Still barely outside the realm of a hello world really.
Now, for this little project I am actually more interested in the ASN part of the problem than I am in the XML parsing so I looked for a parser. I came across the
autumn project which references a parser written by
Dr. Ir. Frank Vanden Berghen which was appealing as it was relatively small, portable and self contained. You can
find the files here.
Now for the fun part. When attempting to compile my newly added class was throwing a dozen or so errors that didn’t exactly make sense to me. I was prepared for some pretty ugly work in trying to port this thing from GCC to the Microsoft compiler, so I didn’t really question these errors. To begin with it was mostly types that were missing. So I would search for the definition of that type and find it in a header file that I was sure was being included. At this point I naively began to move code around in an effort to understand the error. Moving one struct from the header to the cpp file seemed to resolve one error and cause a few more. This seemed to validate my guess that the header was somehow not being included. I had no expectation that this should just work out of the box of course though, so perhaps some of this code was just wrong. I started to chase down the parts of the code that were dependent on flags such as #ifdef WIN32 (I really like how visual studio grays out the code that will not be included based on those conditionals, very nice).
This went on for maybe an hour before I was convinced that this had to be easier. Looking more closely at the build output rather than the error log (which should always be done much sooner than this) revealed this warning :
1>c:\documents and settings\c\my documents\visual studio 2008\projects\xmltoasn\xmltoasn\xmlparser.cpp(82) : warning C4627: ‘#include <Windows.h>‘: skipped when looking for precompiled header use1> Add directive to ‘stdafx.h’ or rebuild precompiled headerThis is one of those steps where I know I should have asked more questions when I first started my project. The project by default included my “main” file, but it also included these two stdafx files (header and cpp) which I briefly looked at but didn’t dig into. The comment at the top of stdafx.h shows this :
// stdafx.h : include file for standard system include files,// or project specific include files that are used frequently, but// are changed infrequentlyWhich if you don’t know what pre-compiled headers are may not make a ton of sense. And it sounds to me like this is optional in any case. Well, it isn’t, at least not if you have the build options on your project set to use precompiled headers which by default I did. Simply adding “
#include <windows.h>” to the stdafx.h file resolved all the problems. So in fact the xmlParser module WAS portable, and I just didn’t have a clue.
The other way to solve this problem is to actually change the precompiled headers setting for your project to not use precompiled headers at all.
So this was a bit frustrating, but all in all a good first foray into this shit, and I’m at least a few steps closer to having a program that actually does something.
And a teaser for all those interface builder lovers out there :
I came across this in reader this morning and was totally blown away by how well the 280 slides application worked. It's really impressive... on non IE browsers. I sent the link to a co-worker to check out and he basically dismissed it as too slow and unresponsive, "typical web app". It took a minute or two to realize the browser was the problem at which point I launched the app in IE 8 Beta (IE 8!) and it performed terribly.It looked terrible, it was jerky and generally just a big let down after the speed of Chrome.
Whatever the technical reasons are, it sucks. Let's hope the new generation of javascript engines (FF3.1 and Chrome) are able to push Microsoft into stepping up. I'm excited about Flex and Silverlight and JavaFX but really I want to believe we can keep pushing the browser without the plugin.
This is a post for myself, to basically bookmark the excellent work of someone else. My post is contributing practically nothing (maybe adding some context/weight for his article) but here it is anyway. ;-)
http://blog.copton.net/articles/linker/index.html
Despite not being an active user of C++ I really enjoyed this post. I actually feel a little smarter and better informed for having read it. Despite the mess in the C++ tool chain being described, this kind of reading actually makes me feel more inclined to dig into this stuff not less. Anyway, filing this one away as something to potentially come back to.
A good friend of mine Sarah believes that the moon landings were a hoax. Despite being a huge science geek , a fan of NASA and a member of the planetary society she subscribes to the idea that man has not in fact walked on the moon, and the entire thing was a lie perpetrated in an effort to win the political war with the USSR. Or something along those lines.
Somehow this deeply disturbs me. Anything coming from Sarah carries considerable weight, so I can’t just discard her opinion. How could it be that the same person avidly following the mars rover mission also believes that we couldn’t land someone on the moon (or rather, didn’t)? I can say that I have not watched/read/been brain washed by the same materials that she has, but I’m expecting to be convinced to do so after this post.
Skepticism is vitally important to science, no doubt. I think scientific thinkers must challenge anything that doesn’t make sense to them. I myself am open to hearing the counter arguments, and I even spent a half hour or so reading the respective wikipedia articles on the matter…
http://en.wikipedia.org/wiki/Apollo_Moon_Landing_hoax_accusations
http://en.wikipedia.org/wiki/Independent_evidence_for_Apollo_Moon_landings
I also think while conspiracy theories are fun (x-files we miss you) they are also wrong 99.99% of the time. In a time where science is considered elitist and unnecessary in one of the most important political, economic and scientific centers on earth, and when NASA continues to face diminishing budgets and smaller mandates it seems terribly unproductive to undermine those efforts being made by real engineers and scientists by giving credence to crack pot theories about hoaxes.
Consider how difficult it is to keep a secret. Imagine the incentive to those cynical people out there who wish to undermine the real achievements of science. Remember the movie contact and Ocham’s Razor? Do we make hundreds of assumptions about the ability for hundreds of people in the government, at NASA and elsewhere all keeping a secret about the landings? That the telemetry mirrors left behind were done by unmanned missions (and that we had the robotics capable at that time to do so?) That the long documentation trail left behind from all the steps leading up to Apollo 11 were somehow part of it? That the FIVE additional moon landings (after the public had already lost interest) were also faked just to add weight to the first faked landing? Or can we assume that no such plot exists and that NASA’s account is roughly accurate? I realize you can flip this and play the other side, but you can read the articles for the details rather than me iterating through the arguments that have already been made on both sides.
I have to admit, I want to believe. I want to believe that we really did achieve the mantel of a moon landing. That we as a culture were able to step outside of our regular bullshit to come together and accomplish something truly spectacular for mankind.

LRO - finally time to shut up the crackpots
In any case, the only real reason I started this post, besides to provoke you Sarah, was so that I could mention the upcoming
Lunar Reconnaissance Orbiter , a mission I will be really looking forward to. It looks like we’re going to get a lot more familiar with our friend the moon. This can only be a good thing as privatized space exploration steps up and produces more tourism and public interest in things beyond our humble planet. The moon may seem a bit provincial at this point, but if you were to seriously consider visiting it (when you make your millions on the internet) do you not get totally stoked? It seems like the next logical jumping point for our more grandiose visions. LRO is launching in early 2009 from Cape Canaveral this mission will include (from wikipedia)
- Characterization of deep space radiation in Lunar orbit
- High-resolution mapping (max 0.5 m) to assist in the selection and characterization of future landing sites
And onboard instrumentation will most importantly include :
LROC — The Lunar Reconnaissance Orbiter Camera (LROC) has been designed to address the measurement requirements of landing site certification and polar illumination.[11] LROC comprises a pair of narrow-angle cameras (NAC) and a single wide-angle camera (WAC). LROC will fly several times over the historic Apollo lunar landing sites, with the camera’s high resolution, the lunar rovers and Lunar Module descent stages and their respective shadows will be clearly visible. It is expected that this photography will boost public acknowledgement of the validity of the landings, and discredit the Apollo conspiracy theories.[12]
It will be nice to put this to rest. Long live Elvis.
Consumption is one of those things that is on my mind a lot. Both economically as I aim to live debt free and with as little "stuff" as really needed as well as in other forms of energy. Buy local, buy less packaging, drive less, eat less! It goes on and on.
One of the really interesting things with looking at google appengine is their metering and logging of your application. The GAE has limits on how much disk, cpu and bandwidth your application can consume before you have to pay for those resources.
(some stats on a very infrequently used blogquotes app)
This model of utility computing has been something that has been kicked around and toyed with for literally four or five decades. In the beginning it was envisioned that computing would be just like the electrical grid, and you would pay for computing resources in much the same way as you do now. This was back when no one ever believed that a household could use or would need a computer that took up an entire room.
That of course all changed, and we drifted to the current state where everyone has their own (or three). Are we are drifting back to a utility model again with the usefulness of having your data live in the cloud? I know I certainly care less and less about the machine I happen to be using when accessing my data. If the data is in the cloud and therefore accessible anywhere you go, and more importantly from any device you choose (iPhone!) then it naturally just makes sense to perform operations on that data within the cloud as well. Why bring it all down to the client to compute values? Why own multiple computers and have idle processors and half empty disks? (wish I had that problem actually) I think it's a bit early to signal the death knell for the personal computer, far from it, but it certainly gets you thinking.
In terms of energy consumption these are all having significant impact on the overall picture. There still exists an incredible amount of power on the client machine that is largely going untapped with increasingly thin clients (but of course that is reversing now too) and that power is going under utilized when we have servers that are performing the same poorly crafted functions doing the work millions of times over for every page view etc.
There was
a blog post in Jan 2007 that talked about how much energy would be saved if google switched from white to black. This post evolved into a
full on article on the topic, and a website (
Blackle) with a counter for energy saved.
This is all very interesting to me, but to get to my point... Using GAE and looking at very precise measurements of the resources my code and application are using was an incredible moment of perspective for me. Here I am, looking at a direct correlation to the algorithm I choose and a measurable amount of resources being consumed by that decision, amazing really. This is just profiling on the aggregate, but it feels profound. Somehow being in the utility computing frame of mind and looking at my "bill" I am compelled to rethink every aspect of my design to find ways to use less resources. This can only be a good thing.
I came across a nice list of fundamental axioms of development on reddit this morning that made me a little pumped. Pumped because I’m in the middle of a big transition at work that in a lot of respects has me starting over with a new team and a new mandate.
I’ll be focusing on solutions, custom work and a view towards short term revenue vs long term research and development for products. Given the economic climate, it’s a shift I can understand and on a personal level one I’m looking forward to. I am saddened of course to be leaving the product I’ve spent the last four years working on, but at the end of the day software is software and this is going to be a big challenge for me.
Here’s the list (http://www2.computer.org/portal/web/buildyourcareer/fa035) highlights for me :
EF1. Efficiency is more often a matter of good design than of good coding. So, if a project requires efficiency, efficiency must be considered early in the life cycle.
Q4. Trying to improve one quality attribute often degrades another. For example, attempts to improve efficiency often degrade modifiability.
T1. Most software tool and technique improvements account for about a 5- to 30-percent increase in productivity and quality. But at one time or another, most of these improvements have been claimed by someone to have “order of magnitude” (factor of 10) benefits. Hype is the plague on the house of software.
T1 I believe after having fallen for the tools pitch more than a few times. At the same time though I think one of the differences in the “great programmers are 30 times more efficient than mediocre programmers” comes down to mastery of the tool set. Watch a proficient developer fly through their code and it’s easy to see. On the other hand I’ve seen excellent “users” who fly through a terrible design and become constrained by EF1.
Anyway, for me this is reminscent of the
pragmatic programmers list, which as obvious as a lot of it is really made me focus on the core of my craft. See Jeff Atwood’s site for a quick reference if you have not seen this list before :
http://www.codinghorror.com/blog/files/Pragmatic%20Quick%20Reference.htmWhile I’m at this, I’ve had some accumulated Martin Fowler wisdom around estimates and scoping that I’ve been meaning to post about. Working in custom solutions will mean writing a lot of proposals and giving fixed cost estimates which is going to be a new game for me…
Martin Fowler: Estimates http://www.martinfowler.com/bliki/ThrownEstimate.html <– Technical debt, casting quick estimates
http://martinfowler.com/bliki/XpVelocity.html <- Nebulous Units of Time
and on dealing with fixed scope….http://martinfowler.com/bliki/ScopeLimbering.html <– dragging clients towards a more agile process
http://martinfowler.com/bliki/FixedPrice.html http://martinfowler.com/bliki/FixedScopeMirage.html
I’ve been testing the latest nightly builds of firefox 3.1 over the past few days and while generally impressed with the performance improvements in javascript was quite disapointed that it was causing my iMac to go into frequent hangs where I would see the spinning beachball of death for many seconds before I could continue working again. It became bad enough that I finally had to ditch my firefox testing efforts.
Much to my chagrin the problem continued well after I had stopped using good ole Minefield. I began to explore running processes via activity explorer and just generally clean up my machine. So after uninstalling a bunch of apps and services I wasn’t running anymore and still experiencing the same problem.
At this point I was worried because the cpu was not the issue, iTunes would continue to play with no problem (and even respond to the hotkeys on my keyboard for switching tracks) it was just the UI that was freezing, and generally as I was opening files. Disk issue? Memory? Maybe even something where the network was introducing some latency? After some googling and consternation over my potentially failing disk I finally did what I should have in the first place and started to dig into the system logs via Console.
Sure enough one group of messages stood out right away…
06/09/08 9:21:29 PM com.apple.ATSServer[14462] ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
06/09/08 9:21:29 PM com.apple.ATSServer[14462] 2008.09.06 21:21:29.63
06/09/08 9:21:29 PM com.apple.ATSServer[14462] ATSServer got a fatal error (status: -4) while processing a message (id: 20) from pid=14309.
06/09/08 9:21:29 PM com.apple.launchd386 Throttling respawn: Will start in 10 seconds
06/09/08 9:21:39 PM com.apple.ATSServer[14465] ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
06/09/08 9:21:39 PM com.apple.ATSServer[14465] 2008.09.06 21:21:39.90
06/09/08 9:21:39 PM com.apple.ATSServer[14465] ATSServer got a fatal error (status: -4) while processing a message (id: 20) from pid=14309.
06/09/08 9:21:39 PM com.apple.launchd386 Throttling respawn: Will start in 10 seconds
06/09/08 9:21:41 PM quicklookd[14463] [QL ERROR] ‘Creating thumbnail’ timed out for ‘<QLThumbnailRequest /Library/Fonts/LiberationSans-Regular.ttf>’
06/09/08 9:21:50 PM Console[14309] Failure with ATSFontGetUnicodeCharacterCoverage(). Disabling font fallback optimization for characters not renderable.
06/09/08 9:21:51 PM com.apple.ATSServer[14468] ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
So the ATSServer (Apple Type Server) was choking and it looks like the beachballs I was seeing were related to the throttling of the respawn of the server. So I’d be staring at a beachball for up to 10 seconds while the rest of the OS hummed along fine. A quick google search revealed the most common reason for this kind of failure is a corrupt font. At this point I shot around in my chair and asked my wife pleadingly and only somewhat accusatorily whether she had by any remote chance installed any fonts lately….. Yes. So I gave her control of my screen so she could clean up what had been added and like magic the beachballs ended. No reboot or anything required, ATSServer has not crashed since and I am writing this in Minefield 3.1b1pre with no problems! (sorry to blame you firefox)
Sadly I do not have the patience to go through the exercise of finding which fonts specifically caused the problems. I really don’t have much use for the extra fonts so I’m just as happy to have them all gone. Still hopefully this helps someone.
Now if I could just clean up all these damn mds errors that keep cropping up …
mds[34]: (Error) Import: importer:0x84b600 Importer start failed for 501 (kr:268435459 (ipc/send) invalid destination port)
A million bloggers all posting on the same topic, why shouldn’t I join in. The Google chrome team has got to be enjoying themselves right now. I read the comic yesterday and really enjoyed it. Seeing a company I can’t help but admire sit down and rethink the browser in so thorough of a manner is inspiring. Even just the QA involved is pretty damn impressive.
I’ve been using the chrome browser for a day now and have to same I’m pretty happy with it. I can already feel a need for some of the firefox extensions that I rely on so heavily, but at the same time I feel more productive and less distracted in this browser than I do in firefox. It’s FAST, really fast on my machine at work. I can’t wait until this is available for my mac.
I really enjoyed this article from John Siracusa, it sums up nicely what I find so inspiring about this and points out the real motivation for Google to create yet another browser.
http://arstechnica.com/staff/fatbits.ars/2008/09/02/straight-out-of-compton
(I’m almost regretting my recent commitment to developing an RIA in silverlight! Where oh where are my first class developer tools for browser based development…. )
Regression is a nasty issue. Ongoing regression from bug fixes can be a pretty clear indicator that there are some serious problems with your code base, your process, your team or all of the above. As an example case consider the effect of moving from 1 in 5 of all bug fixes causing an unrelated issue to crop up to 1 in 10. Given an imaginary scenario where 1000 bugs are found (a medium size project) and a team is closing 20 of those bugs a day then in an extremely simple model we have just added two weeks to our timeline simply from regression issues. (handy chart from google spreadsheets below)

Of course its much more insidious then that though in the real world. For one, regression bugs only pop out at you the minute they are introduced if you’re lucky (they are obvious). More likely is that about half of them will show themselves and the other half will start cropping up near the release date during regression passes. If you alter the model above to show that you’ll see little bulges near the end of the line that start to make time lines feel very elusive and untrustworthy. And given that no QA process is perfect you have to believe that whatever is causing you to introduce those bugs that you are seeing is also causing bugs that are yet to be found.
The importance of quality can never be over-stated, and the effect of poor quality can have a really dramatic impact on a team as well as your customers. Here you are, slaving over your own code, crafting a well thought out and tested solution to a problem, only to have someone else come along and break your code with their fix. Here you are, proudly about to successfully bring a feature out of the QA phase and into the hands of customers and all these elements that you had already seen work are failing. How quickly your trust in your fellow developer begins to wane.
Here though is a problem that I have come to see the light on as being truly systemic. Yes there are horrid developers, and yes there are some difficult technologies, and yes some level of regression is inevitable…. but levels of regression like those that I’ve seen can usually be traced back to process, to your design and architecture, to your requirements and most importantly to your culture.
In terms of process there are some stock answers to bringing this number down like TDD and constant refactoring. I believe in both of these, but in my experience these can be difficult to enfuze into a culture. Without full buy-in and a cultural shift in developers these are just more TLA’s to throw on the steaming pile of buzzwords that will help you magically improve.
Having just come to the end of a release of our product in the past few weeks I am looking forward to whittling away at our own regression ratios.
Changes we’re making :
- No more sharing of the bug load. Every developer owns their module/feature/code from design through to maintenance. This include assigning ownership to old modules whose owners may no longer be around. If you write bad code, you will fix more bugs. If you fix more bugs, you will have less time to spend on new bug-ridden features. This will mean our actual bug trends won’t be the pretty descent we’ve worked so hard on achieving. But the overall effect of a self correcting system should help.
- More atomic checkins. Checkins that span branch points, or handling merges of bugs can be extremely error prone with subversion and our current branching strategy. We hope to address this somewhat by eliminating bug fixes that span multiple revisions… Ideally this will involve :
- Patch files attached to the bugtracker for code reviews to avoid multiple checkins when reviews spot errors
- When changes still need to be made to a bug when things are caught in QA then we also revert the original checkin, and checkin again with all changes at once in the new revision.
- Bugs will be closed diligently and new bugs opened rather than morphing the bug over time as new side effects or slightly related bugs are spotted.
- More automated testing. This is last on the list not because it’s least important, but because we don’t expect as quick of an impact as with the other two steps. A major number of the issues we run into remain UI issues. And while WatiN does do wonders for us, it’s painstakingly slow to get the number of tests to where they should be (and keep them up to date).
Lastly just for interest here’s the graph of how we’ve actually done. Black shade are high severity bugs. The first mountain was the release previous where we amalgamated all previous releases into this (migration of existing clients) we had some pretty serious regression in that release after Christmas. The second range is the most recent release which is looking amazing in comparison, though at this resolution you are missing some definite climbs amongst that fall. Definite progress anyway….






